
This is the seventh post in a series about what makes a team effective. Effective means, the team does the right thing to reach its goal.
I’ve seen several projects that started well, but after about one year into the project problems arose. The developers started to do software archaeology before adding new functionality. They simply weren’t sure any more what happens inside their software. So they went from method to method and from class to class to guess what a change would do (or possibly break).
Their software had become a black box.

Once the team cannot predict the impact of a change, estimations are impossible. The change may take one day when everything just works out fine. Or the change may take several weeks because the change results in a cascade of follow-up changes (also known as bugs). If the team can not even roughly estimate what a change costs, the team cannot plan anymore. They cannot say whether a certain feature is worth building (value is bigger than cost). Therefore, they cannot decide anymore what to do to make a profit.
Know your code
The team has to know what their software is capable of to make informed decisions. Furthermore, the team needs to know whether a change to the software results in unwanted side effects or defects.
Specifications
Specifications (or Acceptance Tests) both describe the system and build a safety net for changes. Specifications are executable tests for which a report in prose (more or less ) can be generated.
Here you can see a piece from the report of the specifications of my state machine implementation in Appccelerate:
Execute transition specifications
When firing an event onto a started state machine
- should execute transition by switching state
- should execute transition actions
- should pass parameters to transition action
- should execute exit action of source state
- should execute entry action of destination state
When firing an event onto a started hierarchical state machine with source and destination having different parents
- should execute exit action of source state
- should execute exit action of parent of source state
- should execute entry action of parent of destination state
- should execute entry action of destination state
- should execute actions from source upwards and then downwards to destination state
The team can discuss these specifications with the stakeholders and should therefore be written in the language of the stakeholders.
Here you can see a piece of a specification in code:
[Subject(Concern.Transition)]
public class When_firing_an_event_onto_a_started_state_machine
{
…
Establish context = () =>
{
machine = new PassiveStateMachine<int, int>(); …
};
Because of = () => machine.Fire(Event, Parameter);
It should_execute_transition_by_switching_state = () =>
currentStateExtension.CurrentState.Should().Be(DestinationState);
It should_execute_transition_actions = () => …
It should_pass_parameters_to_transition_action = () => …
It should_execute_exit_action_of_source_state = () => …
It should_execute_entry_action_of_destination_state = () => …
}
When a change introduces a defect there is a big chance that one of the specifications will fail. Therefore, we execute our specifications on every commit to the main source repository on our continuous integration server. The specifications are however only a part of our automated test suite and may only catch big problems. We have unit tests for small problems.
We practice Acceptance Test Driven Development (or Behaviour Driven Development BDD) and write the specification/test first to check whether it really fails and then add the needed functionality to pass the specification/test.
Auto-documentation
Specifications are great to document the functionality of a system. For documenting how the system is structured and functions internally, we need something different. Of course we could manually document this things, but let’s be honest, we don’t like writing documentation and the documentation is out-of-date the next day. There is a better way. Let’s generate most of this documentation.
Here you can see an example of an semi-automatically generated documentation of a state machine:
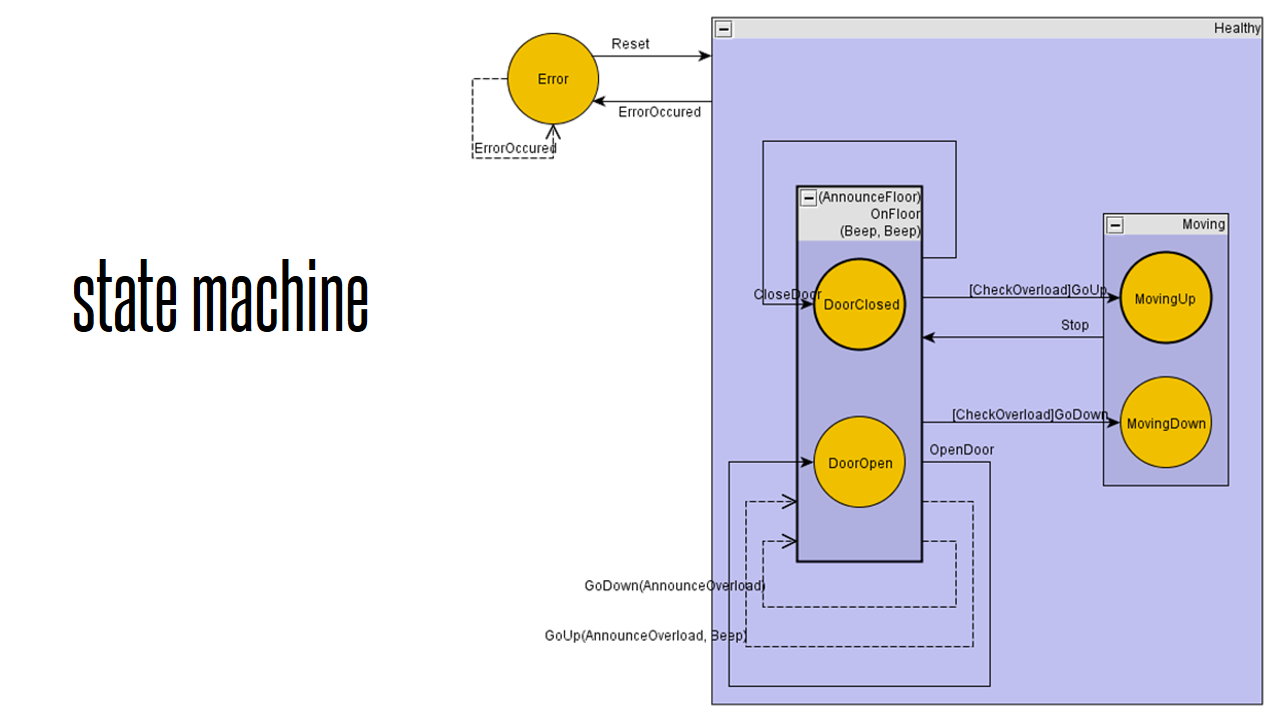
The state machine of Appccelerate allows to write a yEd GraphEditor file to the disk that then can be put in a nice layout by yEd Graph Editor. You can generate state and event tables, too.
We also generate an automatic documentation of the structure of our system with Ninject.Features. This is an example for two applications: Enterprise Application and Standard Application – two applications from a product family. The Enterprise Application supports all features of the Standard Application plus Document Transformation. This image is generated from code (again using yEd Graph Editor for the layout):
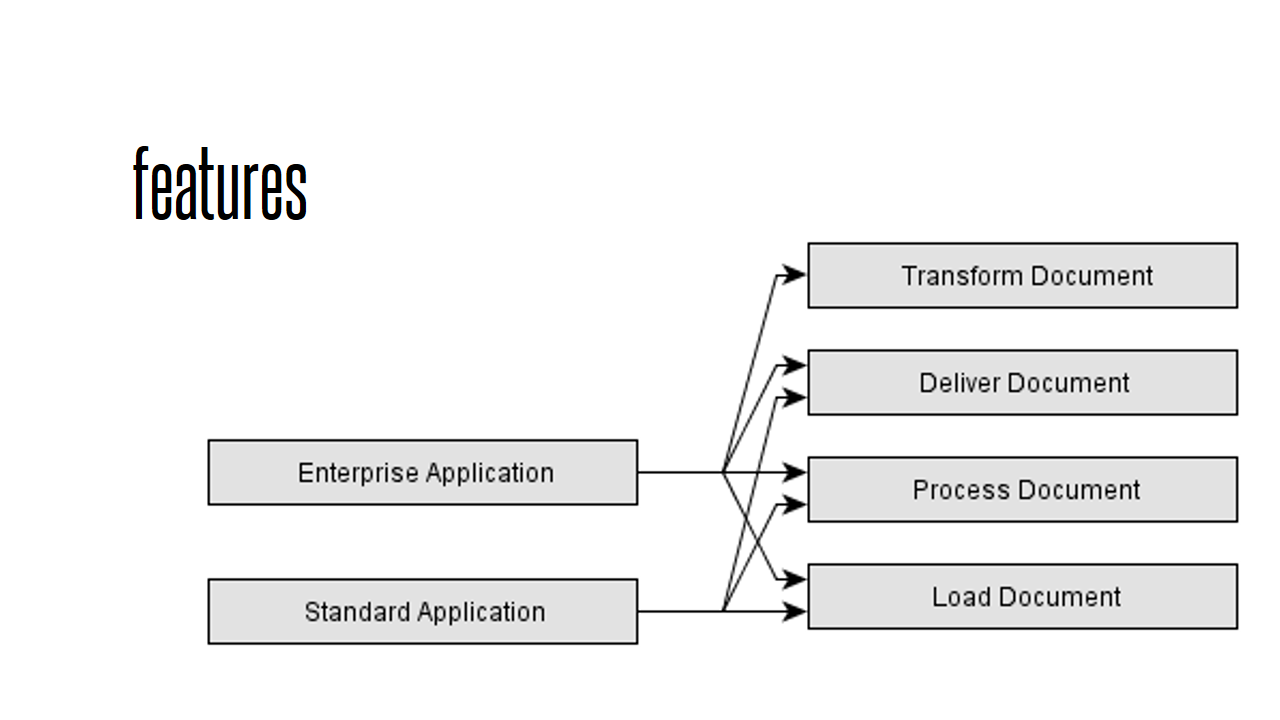
In order to automatically document the structure, we use feature classes in our code that look like this:
public class StandardApplicationFeature : Feature
{
public override IEnumerable<Feature> NeededFeatures
{
get
{
yield return new LoadDocumentFeature();
yield return new ProcessDocumentFeature();
yield return new DeliverDocumentFeature();
}
}
public override IEnumerable<INinjectModule> Modules
{
get
{
yield return new FileSystemModule();
yield return new LoggerModule();
yield return new StandardApplicationModule();
}
}
}
These feature classes describe how the system is built together. A feature describes its sub-features. Sub-features can be shared be multiple features. We use Ninject as our Inversion of Control Container and therefore the feature defines which Ninject modules (they define how interfaces our bound to classes and their live time) are used to build the feature.
You can use a similar approach to document bootstrapping of systems, flow in a workflow and much more.
Putting all together
Our system is built from several features that have sub-features that have sub-features …
Every feature has its specifications describing how the feature functions. The result is a hierarchy of specifications. We keep duplication in specifications to a minimum by specifying functionality of a sub-feature on a more abstract level in the outer specification. E.g. sub-feature specifications describe what happens exactly when writing data to a file, outer feature just states that data is written to a file.
Finally, we use auto-documentation to document the feature hierarchy and things like state-machines, bootstrapping etc.
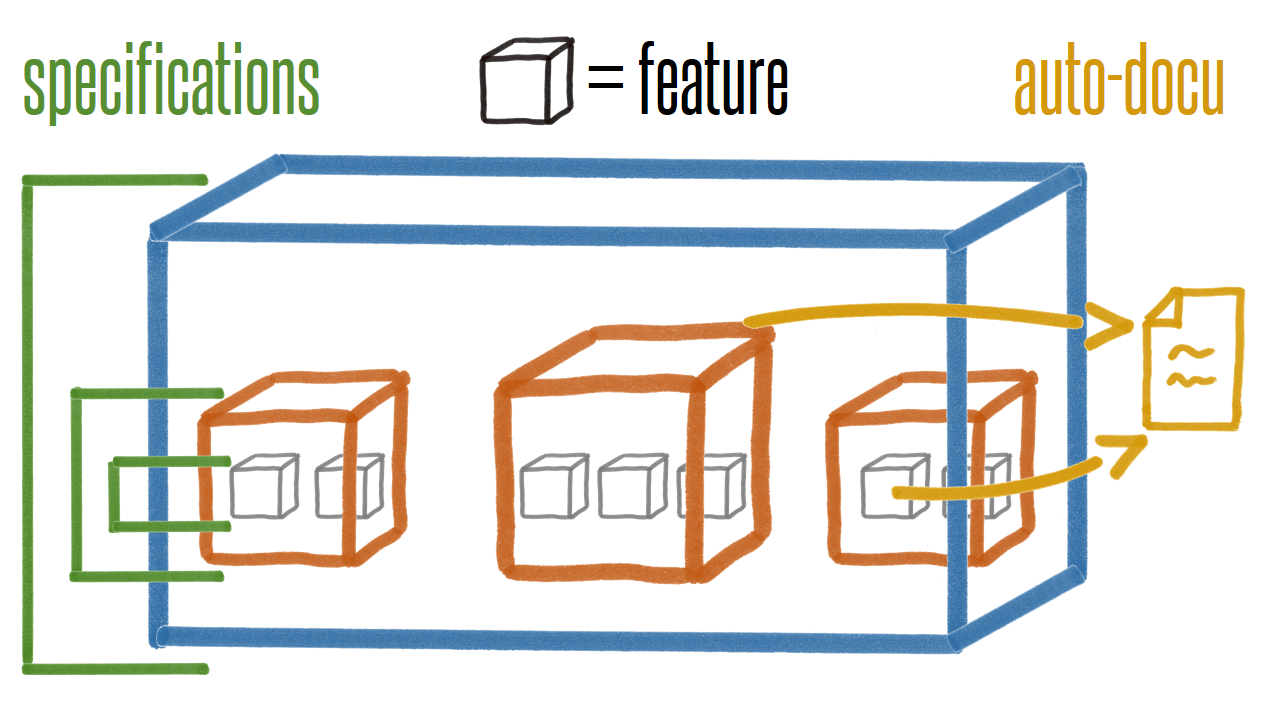
This gives us a very flexible design that can easily be changed and the documentation changes with the code.
Conclusions
If you want to make informed decisions, make sure your team knows their code. Specifications and auto-documentation help keeping an up-to-date documentation.
RT @planetgeekch: Effective teams: know your code http://t.co/zkEzjUQHL4
RT @planetgeekch: Effective teams: know your code http://t.co/zkEzjUQHL4