
In my last installment I gave a brief overview over Service Bus for Windows Server. In this post I’m going to look at High Availability and why it is important. In my last project my job was to help a team out building a robust and reliable infrastructure which leverages Service Bus for Windows Server. On the first day we sat together and discussed the various questions the team had regarding reliability and availability. The first question started like that: “What can we do in code when the Service Bus for Windows Server is not available?” My answer was the following: “In code? Besides trying to reconnect to the Service Bus a configurable amount of time you cannot really do much. If your most important communication layer is down for a longer period of time your system should detect that problem and gracefully shut down its services. If you are not specifically building for an occasionally connected system your infrastructure needs to be made reliable and available. Trying to solve those concerns in your systems code is a waste of time and money.” We shaked hands, the customer said thank you and I went home. Problem solved without writing a single line of code 😉 Just joking!
“Use Messaging to transfer packets of data frequently, immediately, reliably, and asynchronously, using customizable formats. [..]” This quote from the Enterprise Integration Patterns book from Gregor Hohpe and Bobby Woolf shows that one of the fundamental principle of messaging is that the messages need to be transferred immediately and reliable. In order to achieve this our Service Bus infrastructure needs to be reliable and highly available. Because Service Bus for Windows Server is a broker-based transport the producers and consumers rely on the availability of a centralized infrastructure. But what could possibly go wrong?
- Network connections can fail or be aborted
- The producer and/or the consumer can have hardware issues and eventually crash
- If the producer and/or the consumer keep running but the network has been interrupted, the channel between them and the broker has to be reestablished.
- In order to prevent message lost the infrastructure must be able to cope with restarts, broker hardware failure and even broker crashes.
- Never forget that the underlying operating system has to be updated too and systems even restarted (thanks Windows!)
- I’m sure you can even come up with more scenarios!
But how does Service Bus for Windows Server achieve high availability? Service Bus for Windows Server has two aspects to high availability which have to be taken care of. These are the compute layer and the storage layer.
The compute layer needs at least three Windows Server machines to be highly available. This allows you to lose one machine in this so called farm. The machines joined in a service bus farm communicate under each other over the Windows Fabric controller.
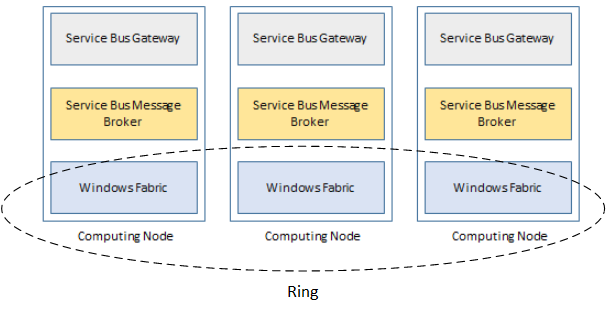
Windows Fabric controller manages dynamic message container placing inside the farm in the case of a messaging broker service crash or recycle or even in the event of a complete node recycle/shutdown only with a small interruption. This means computation can carry on almost immediately.
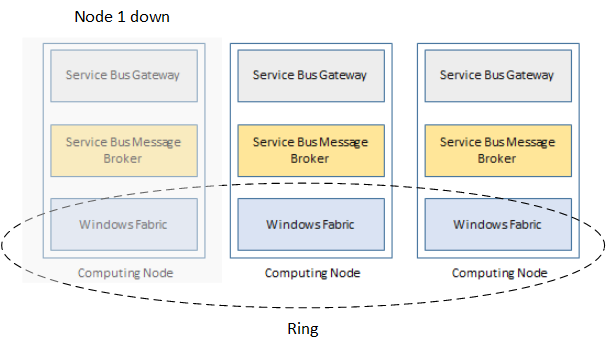
If a server has more than one container, the fabric controller automatically rebalances the compute capacity by reassigning the containers to a specific messaging broker service. This load balancing mechanism is also triggered when server administrators create new message containers or remove existing ones. New servers can be joined into an existing farm automatically by issuing a few PowerShell commands which we will cover in next installments.
For the storage layer Service Bus for Windows Server has no out-of-the-box solution. But because the underlying storage layer is based upon Sql Server you can use Sql Server Mirroring or AlwaysOn features of newest Sql Server Editions.
The next installment will cover how to setup the compute layer of Service Bus for Windows Server to create a three node cluster.
RT @planetgeekch: Service Bus for Windows Server High Availability http://t.co/FOG6NOX2C1
RT @planetgeekch: Service Bus for Windows Server High Availability http://t.co/FOG6NOX2C1