These are the slides with some notes from my talk about software architecture when developing in an agile way. Contents
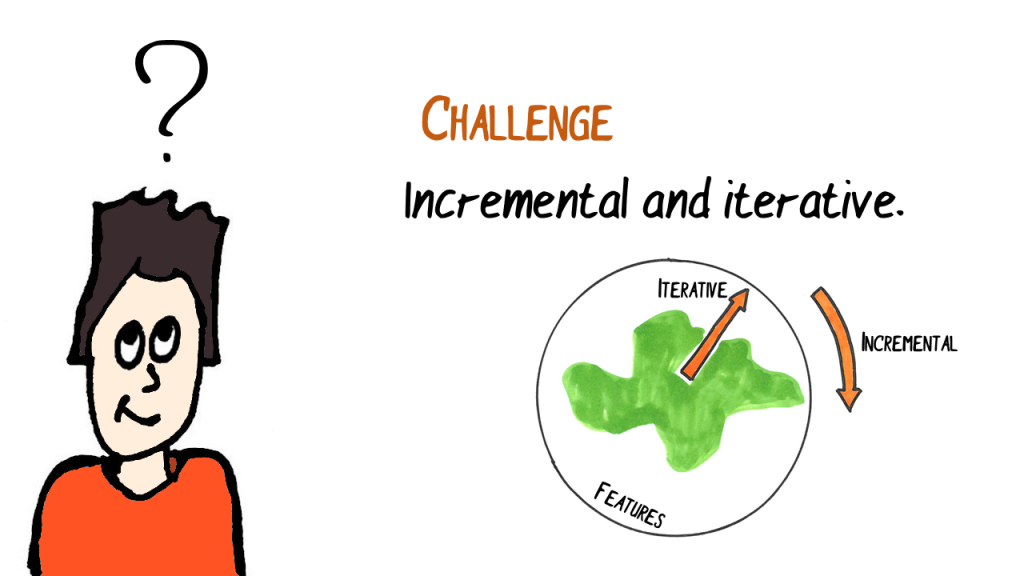
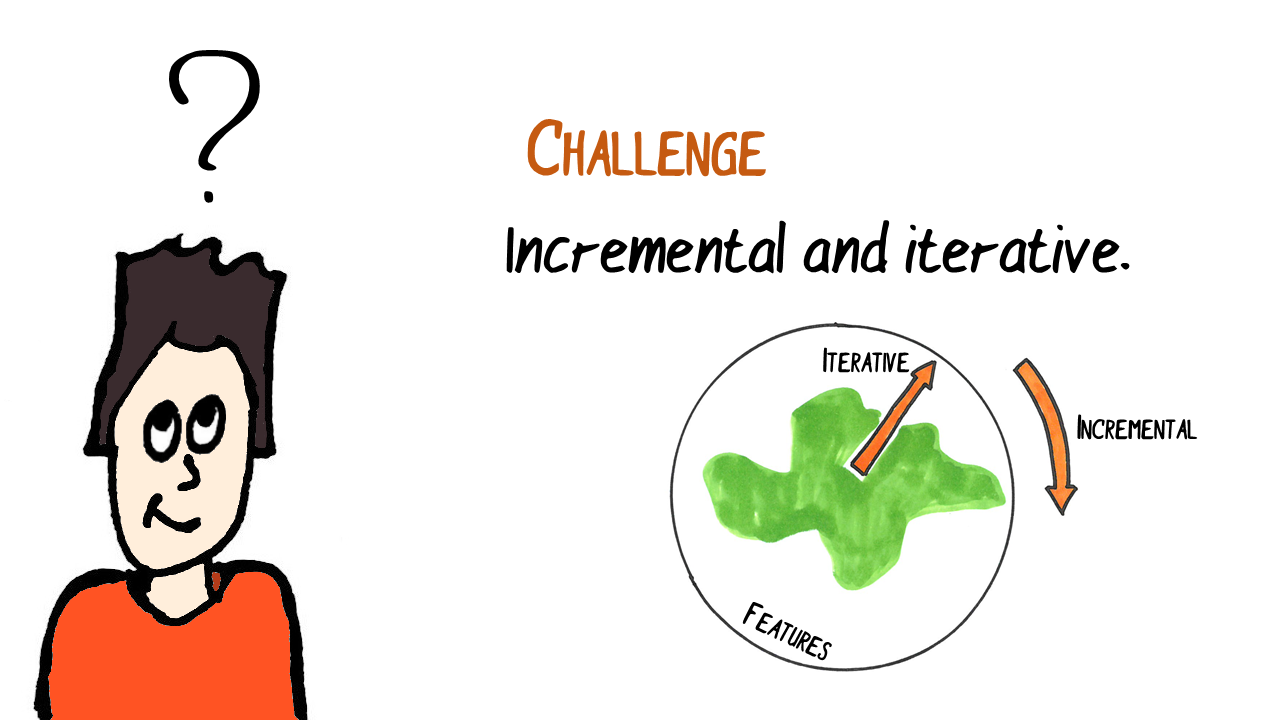
When we build software with an agile approach, we build features incrementally and iteratively.
Incremental = one feature after the other.
Iterative = we build the first version of a feature, get feedback and improve it in the next iteration.
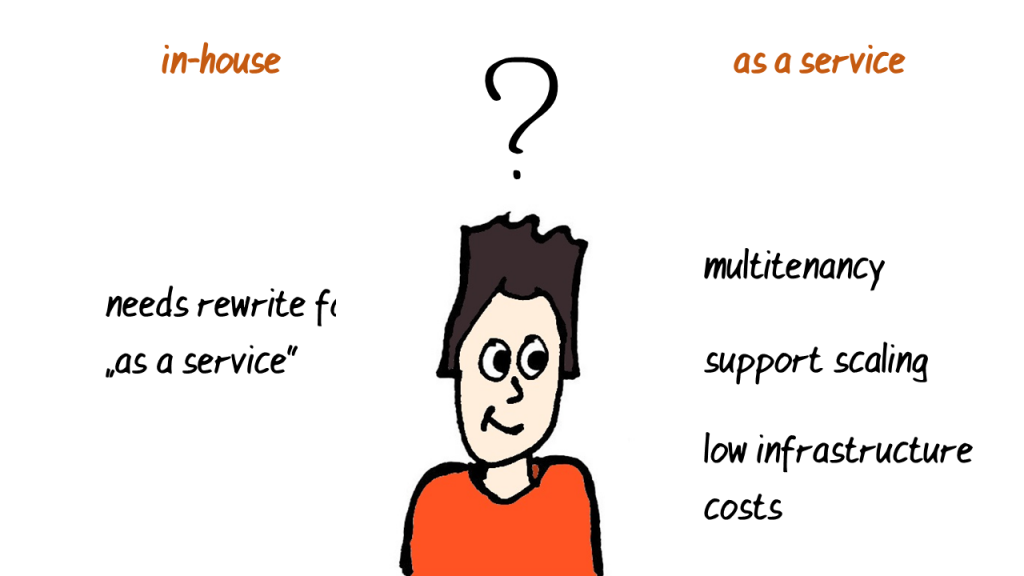
But how can Max define a software architecture incrementally and iteratively? Architecture is about the hard and costly decisions. Max wants to get them right from the start!
The first in-house version does not need multi-tenancy, does not need to be scaled or be optimised for low infrastructure costs. But what happens when Max ignores theses requirements for now? Does he have to throw away version 1 to build version 2?
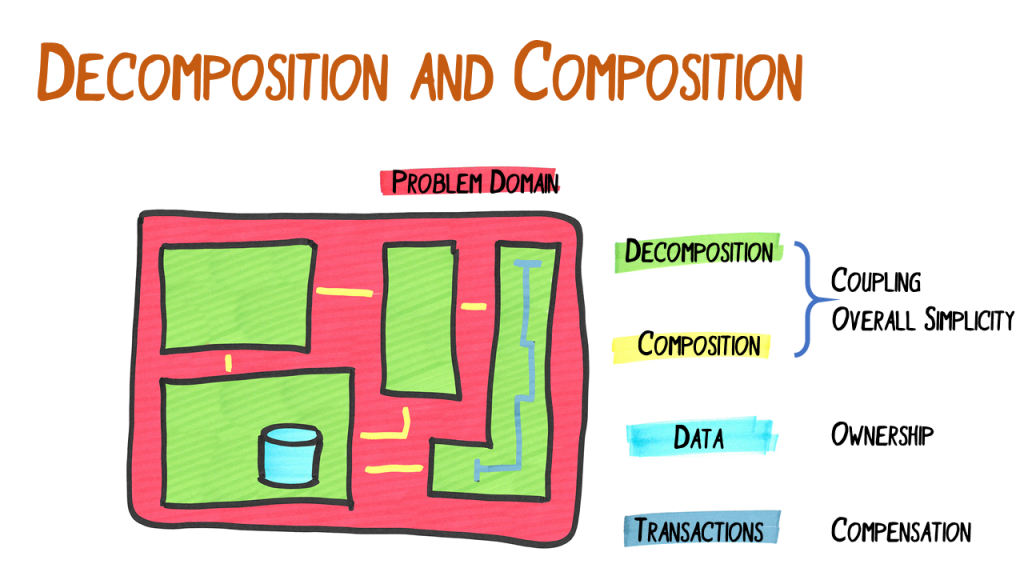
Max decomposes the problem to be solved into subproblems and finds solutions for the subproblems. The subproblems should be mostly independent of each other. They never are truly independent because we still build a single system, but the interface should be minimal.
Think for example about a webshop. There is a catalogue that lets you see what you can buy. Then there is the cart where you put what you want to buy. These are two mostly independent subproblems. The only data that needs to be passed from the catalogue to the cart is the ID of the article and the number of items. The same goes for the pricing subproblem, the recommendation subproblem, and so on.
Then Max designs the composition of the partial solutions into a solution of the whole problem. This is an iterative process because decomposition and composition are interdependent. Max seeks a solution that maximises overall simplicity.
Note that the challenges of the composition are often neglected. “Hey, we have these 100 very small and easy to understand microservices!”, “Yes, but nobody gets them to interact correctly!”
When Max decomposes the problem into subproblems, the domain data needs to be split as well. There should only be one part of the system that holds ownership of a certain part of the data. Only the part with ownership is allowed to change the data. All other parts – if needed – just get a read-only copy of the data. So part of designing the composition is to define what data is shared and how it is shared, e.g. with events notifying about changes made.
When the data is split into several mostly independent parts, transactions get difficult. Most times, it is better to use a transaction solely within a single partial solution. If a process runs through several partial solutions and something goes wrong, then we tell the partial solutions that already succeeded to compensate whatever they did to regain a consistent state.
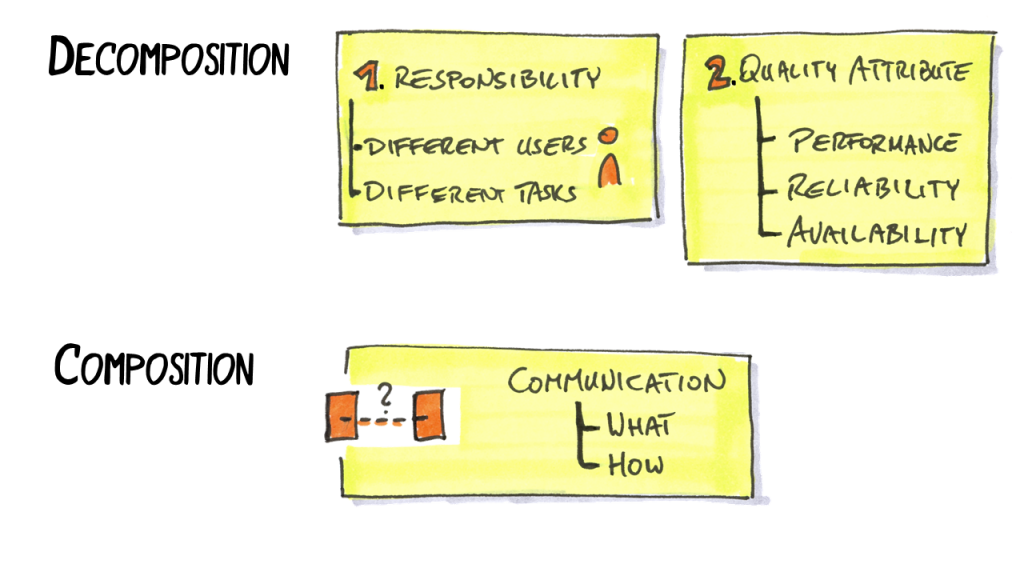
Some questions you can ask yourself to find subproblems for decomposition: Are there different kinds of users? Are they working on independent tasks? Or are there very different requirements regarding quality attributes like performance, reliability or availability?
When designing the composition, consider the communication between the subproblems. What data needs to be exchanged and how should that data be exchanged – synchronously or asynchronously, on what transport medium?
Once the system is decomposed into several parts, these parts can be built incrementally and iteratively.
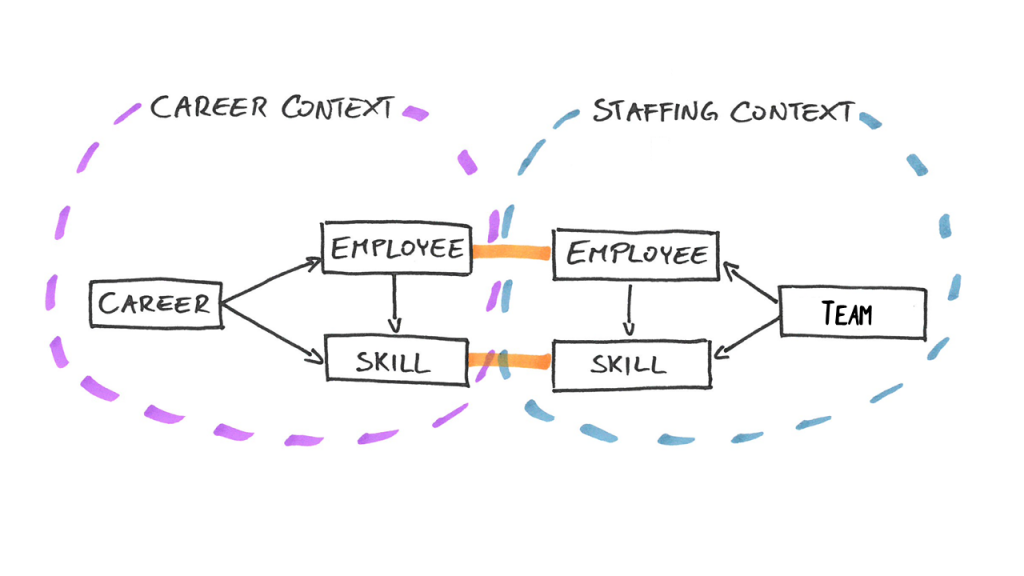
Max decides to decompose the matching problem into two subproblems: career subproblem and staffing subproblem. In architecture, we often call the subproblems contexts according to domain-driven design (DDD).
The career context models the employees with their skill on a timeline – their career. Employees forget about and learn new skills over time.
The staffing context models the team with its needed skills and the employees with their current skills.
There are employees and skills in both contexts, but they are modelled in a slightly different way and meaning. For example, in the staffing context, only current skills are relevant and the employee may consist of less data than the employee in the career context.
When an employee is added or when a skill changes, then the career context notifies the staffing context about the change and the staffing context updates its model accordingly.
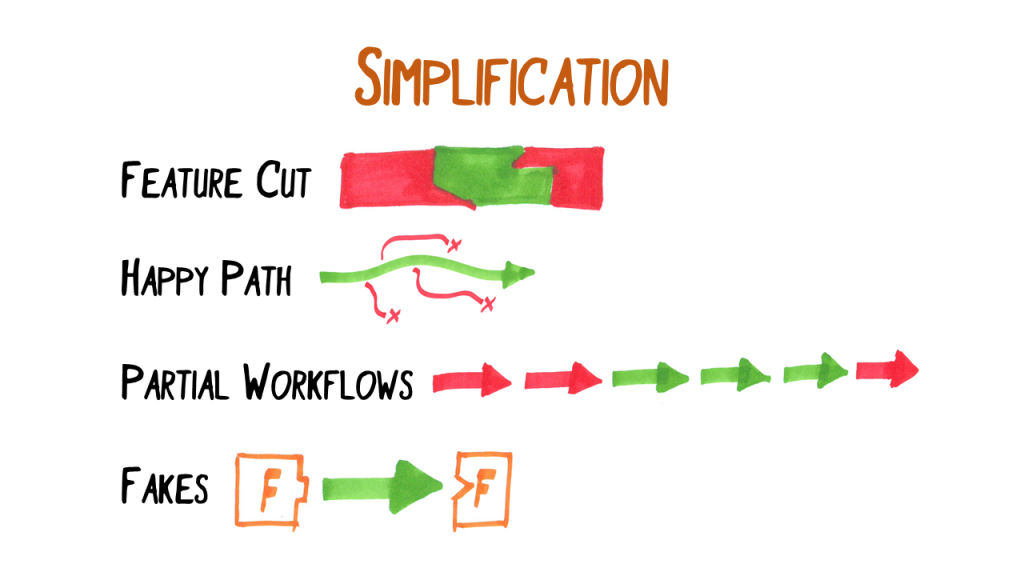
Another important approach to be able to design a solution incrementally and iteratively is to simplify the problem and then add complexity step by step.
The simplest way to simplify software is to cut features. As a rule of thumb: if you cut 25% of the features you can build the software in 50% of the effort. Therefore, cut features, build the software and then add features. We’ll come back to this later.
One special kind of cutting features is to first build the happy path only. Leave everything away that deals with faults, errors and special cases. Later, add the special cases and the error handling and so on.
If your system has workflows consisting of a sequence of steps, you can build just the parts you need feedback on first and leave out the steps prior and after. Then add step by step.
You’ll probably need some sort of fakes or simulations that provide you with input or that consume outputs.
Continue reading: Making decisions with little knowledge
[…] Incremental and iterative […]