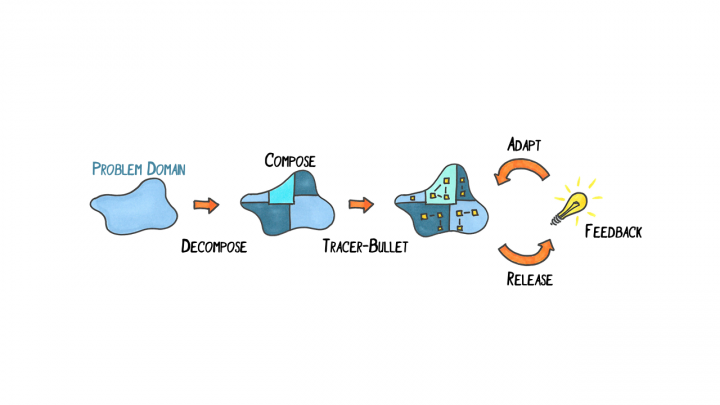
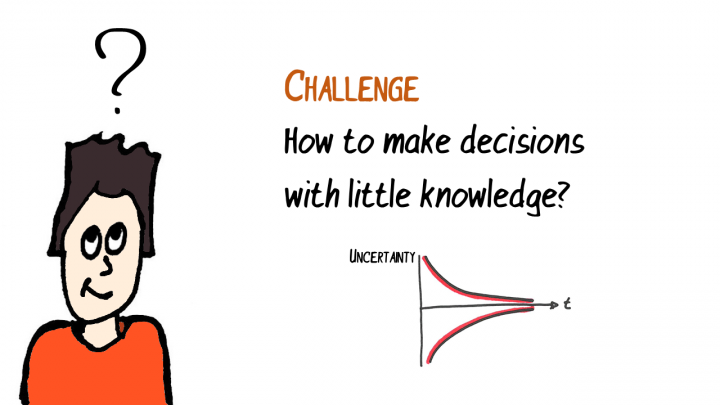
Bi-temporal event sourcing combines storing data as a sequence of events, which tell what has happened with the data, and the data has two associated points of time, one when the data entered the system and one when the data takes effect. This post is about our 8+ years of experience with bi-temporal event sourcing, along with code samples showing how to achieve this. Feel free to skip the code blocks and just read the conceptual parts. But you’ll miss the beauty of F# 😂 This post is part...