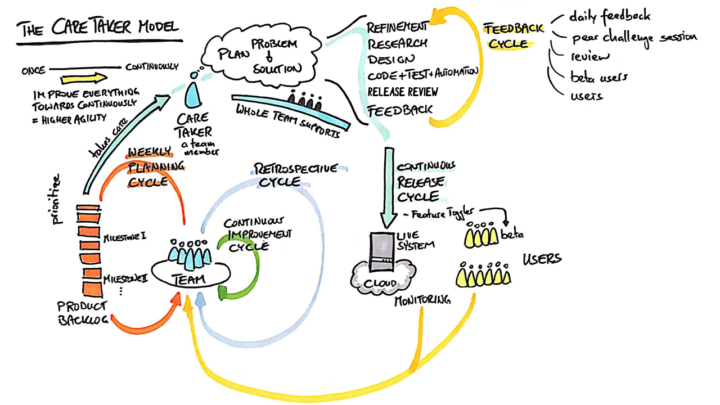
Probably every software developer had to estimate the effort needed to implement some wanted software. And the estimate was likely rather wrong. I collected reasons why this happened to me over many years. And I concluded that the estimation approach is fundamentally wrong. Here are my reasons: