

This is the presentation handout for a presentation I gave at the bbv Techday 2013. Special thanks to Jeffrey Palermo for supporting me. Chopping onions usually makes you cry. This is not the case in software architecture. In contrary! The onion architecture, introduced by Jeffrey Palermo, puts the widely known layered architecture onto its head. Get to know the onion architecture and its merits with simple and practical examples. Combined with code structuring by feature your software is easy to understand, changeable and extendable. Turn your tears of sorrow into tears of delight.

Before I started preparing the talk I wondered myself, whether the topic “how to organize your components and classes in your architecture” is still a relevant topic. According to the reactions to a tweet of mine it still is. Furthermore, why are you reading this post anyway? Before we talk about layering, I want to get rid of a common misconception regarding layers vs. tiers first.
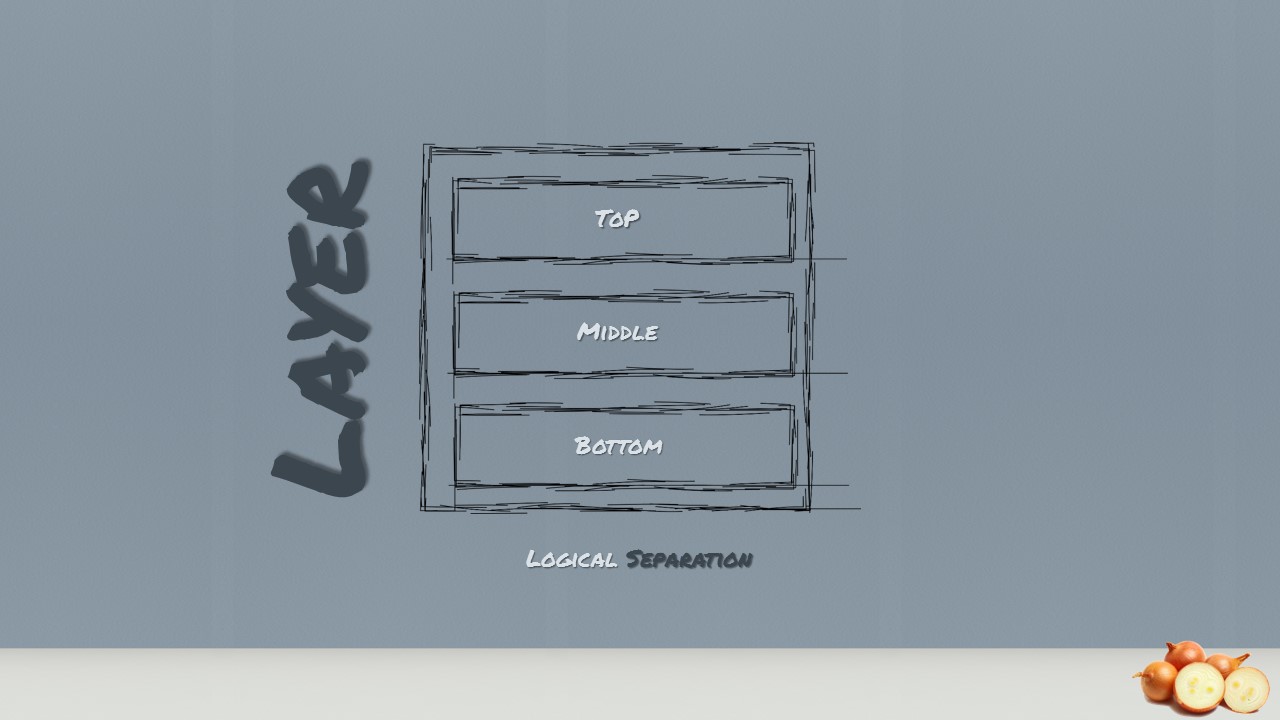
When we talk about layers, we mean the logical separation or division of components and functionality and not the physical location of components in different servers or places.
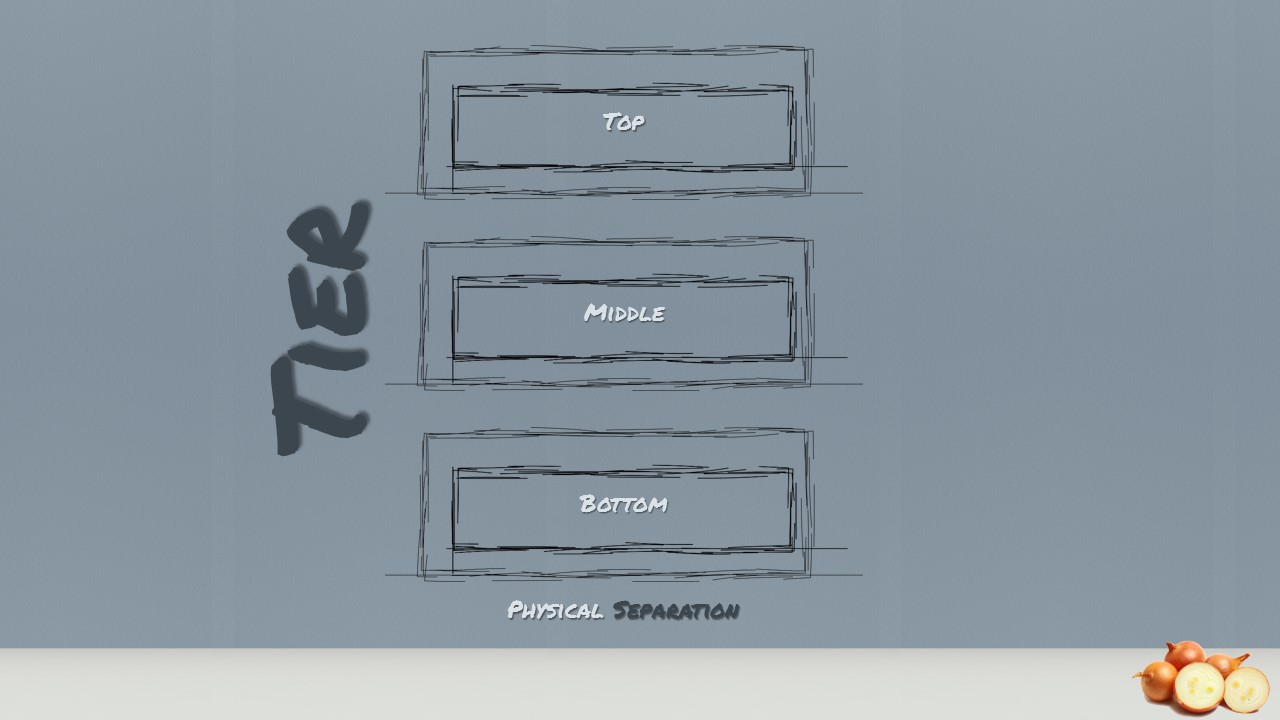
The term tiers refers to the physical distribution of components and functionality in separate servers, including the network topology and remote locations. Tiers are usually used to refer to physical distribution patterns such as “2 Tier”, “3 Tier” and “N Tier”. Unfortunately, both layers and tiers often use similar names. In this presentation, we talk about layers and not tiers! Nevertheless, what is a layer besides a logical separation and when was it introduced?

In the year 1996 Frank Buschmann, Regine Meunier, Hans Rohnert, Peter Sommerlad and Michael Stal analyzed different software systems. They asked themselves what patterns make software systems successful and allow us to evolve systems without developing a big ball of mud. Their knowledge was published in a book called Pattern-oriented Software Architecture – A System of Patterns.

In that book they came to the conclusion that large systems need to be decomposed in order to keep structural sanity. The so-called Layers pattern should help to structure applications that can be decomposed into groups of subtasks in which each group of subtasks is at a particular level of abstraction. The initial inspiration came from the OSI 7-layer Model defined by the International Standardization Organization. This inspired the original N-Layer model.
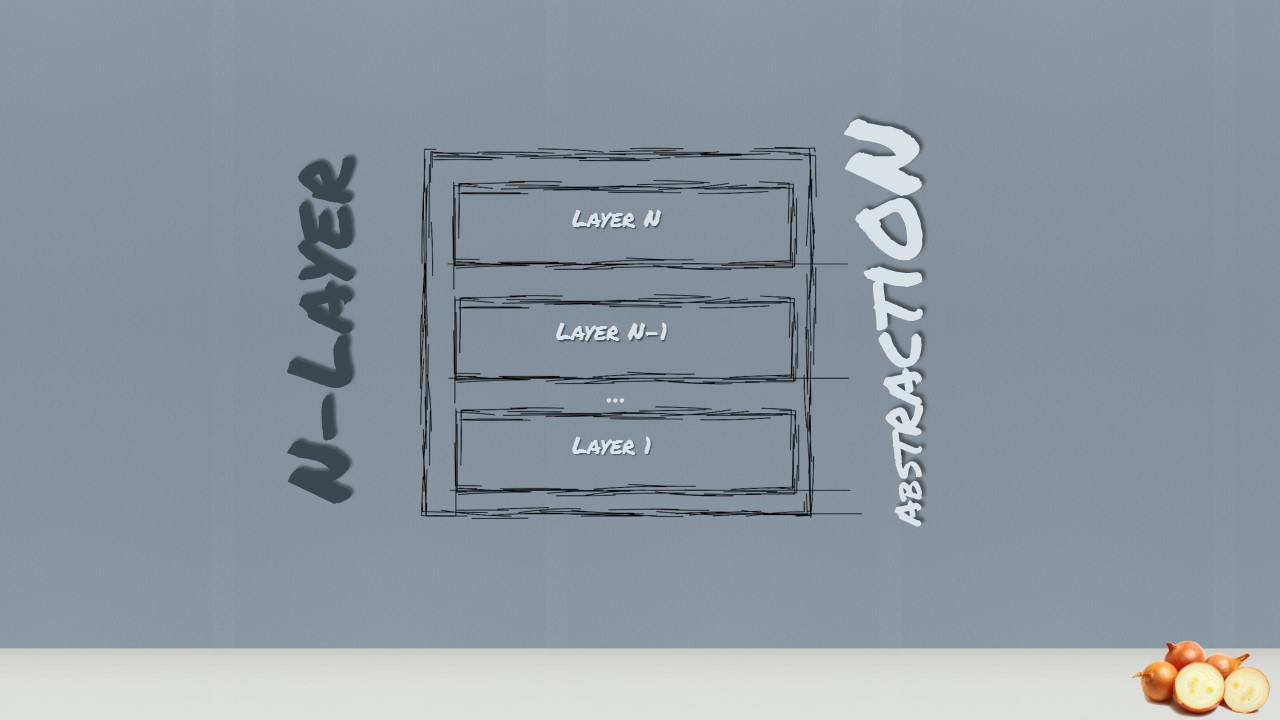
The layer higher in the hierarchy (Layer N+ 1) only uses services of a layer N. No further, direct dependencies are allowed between layers. Therefore, each individual layer shields all lower layers from directly being access by higher layers (information hiding). It is essential that within an individual layer all components work at the same level of abstraction. This approach is also called strict layering. The relaxed or flexible layering is less restrictive about the relationships between layers. Each layer may use the services of all layers below it. The advantage of this approach is usually more flexibility and performance (less mappings between layers) but this is paid for by a loss of maintainability. In order to be able to define layers and put component into layers you have to define the abstraction criterion. For example, the lower levels can be defined by the distance from the hardware on the upper levels by the conceptual complexity. Possible layering could be chosen (top to bottom):
- User-visible elements
- Specific application modules
- Common services level
- Operating system interface level
- Operation System
- Hardware

The common layers they defined were Other books or articles may name it differently but we will stick to that definition. We have the presentation or client layer, the process or service layer, the domain or business logic layer, the data access or infrastructure layer. Sometimes you see the layers above extended with another layer sitting on the left side spawning all layers. This layer is often called crosscutting layer which handles stuff like tracing, logging and other things…
Let us first talk about the advantages of this approach.

If an individual layer embodies a well-defined abstraction and has a well-defined and documented interface, the layer can be reused in multiple contexts. Naturally the data access seems a nice fit for layer reuse.

Clearly defined and commonly accepted levels of abstraction enable the development of standardized tasks and interfaces. After many years of layered architecture a lot of tools and helpers have been invented to automatically map from one layer to another for example.

Standardized interfaces between layers usually confine the effect of code changes to the layer that is changed.

Individual layer implementations can be replaced by semantically equivalent implementations without too great of an effort.

Easy, isn’t it? At least that is what beginners or our customers think it is.

Unfortunately developers often take the layering literally. Sometime later, this happens…
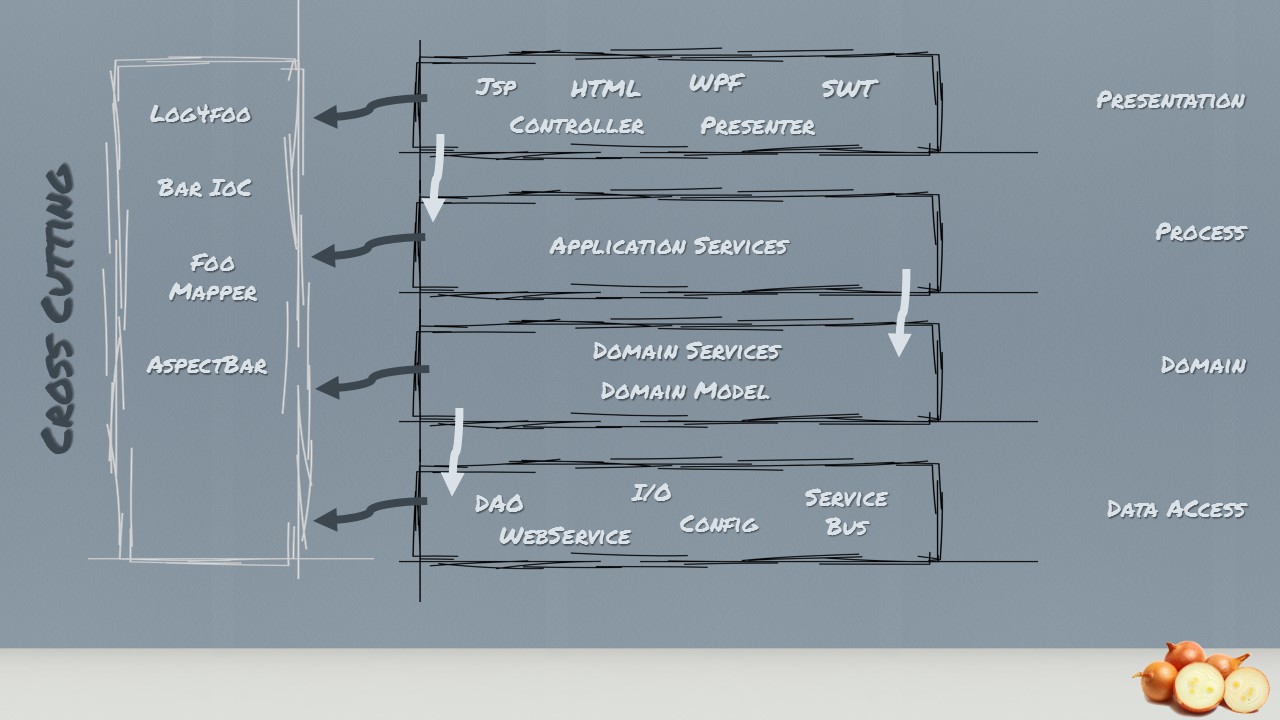
Instead of getting the best out of the benefits of the layered architecture style, we end up with several layer dependent on the layers below it. For example giving the previous layering structure the presentation layer depends on the application layer and then on the domain layer and finally on the database layer. This means that each layer is coupled to the layers below it and often those layers end up being coupled to various infrastructure concerns. It is clear that coupling is necessary in order for an application to be able to do anything meaningful but this architecture pattern creates unnecessary coupling.
The biggest offender is the coupling of the UI and business logic to the data access. Wait a moment. Did I just say that the UI is coupled to the data access? Yes indeed. Transitive dependencies are still dependencies. No matter how anyone else tries to formulate it. The UI cannot function if the business logic is not available. The business logic in return cannot function if the data access is not available. We gracefully ignore the infrastructure because typically it varies from system to system. When we analyze the architecture above in retrospective, we detect that the database layer is becoming the core foundation of the whole application structure. It is becoming the critical layer. Any change on the data access / infrastructure layer will affect all other layer of the application and therefore changes ripple through from the bottom to the top of the application.
This architecture pattern is heavily leaning on the infrastructure. The business code fills in the gaps left by the infrastructural bits and pieces. If a process or domain layer couples itself with infrastructure concerns, it is doing too much and becomes difficult to test. Especially this layer should know close to nothing about infrastructure. Infrastructure is only a plumbing support to the business layer, not the other way around. Development efforts should start from designing the domain-code and not the data-access, the necessary plumbings should be an implementation detail.

https://github.com/danielmarbach/Layer.Factory

And now, how do we get around this drawbacks of the layered architecture?

Onions! What else? We simply move the all infrastructure and data access concerns to the external of the application and not into the center. Jeffrey Palermo proposed this approach called Onion Architecture on his blog 2008. The approach is nothing new. However, Jeffrey liked to have an easy to remember name, which allows communicating the architecture pattern more effectively. Similar approaches have been mentioned in Ports & Adapters (Cockburn), Screaming Architecture (Robert C. Martin), DCI (Data Context Interaction) from James Coplien, and Trygve Reenskaug and BCE (A Use-Case Driven Approach) by Ivar Jacobson. Let us depict the onion architecture.
The main premise is that it controls coupling. The fundamental rule is that all code can depend on layers more central, but code cannot depend on layers further out from the core. In other words, all coupling is toward the center. This architecture is unashamedly biased toward object-oriented programming, and it puts objects before all others.
Furthermore the Onion Architecture is based on the principles of Domain Driven Design. Applying those principles makes only sense if the application has a certain size and complexity. Be sure to reflect properly on that point before jumping blindly into the Onion Architecture. Let us see what Onions combined with Domain Driven Design produces…
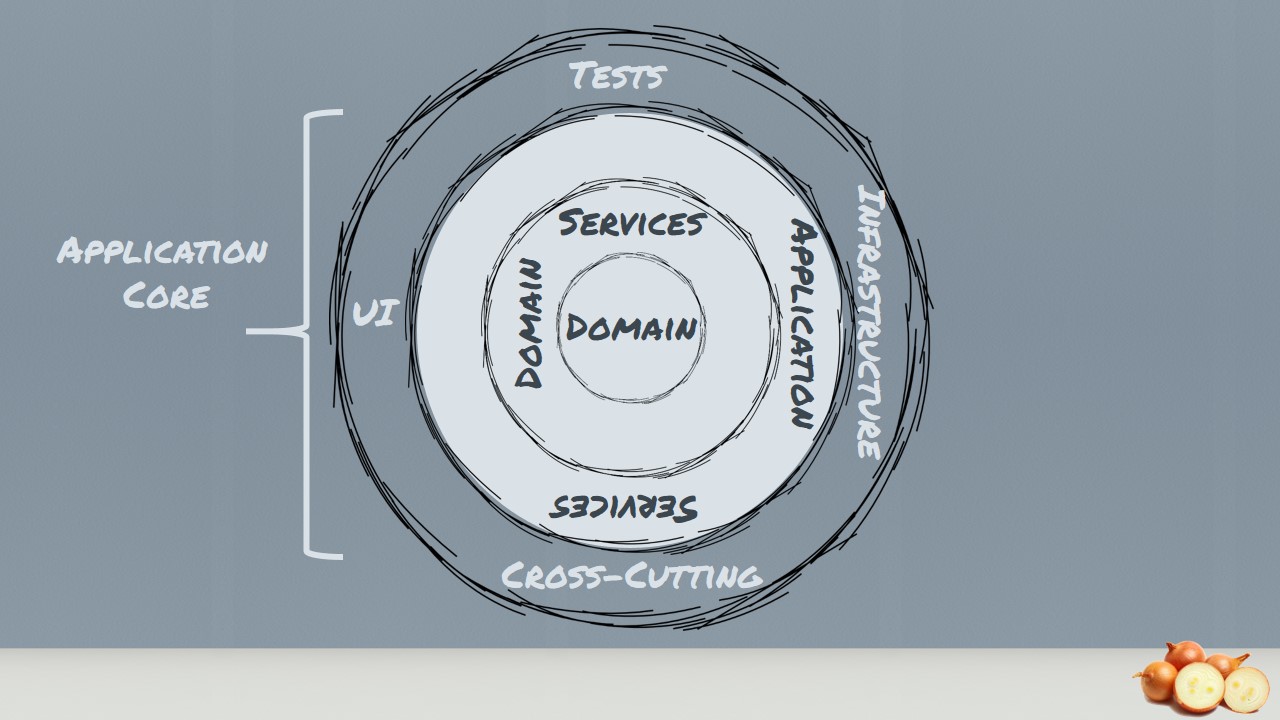
In the very center, we see the Domain Model, which represents the state and behavior combination that models truth for the organization. The number of layers in the application core will vary, but remember that the Domain Model is the very center, and since all coupling is toward the center, the Domain Model is only coupled to itself.
The first ring around the Domain Model is typically where we would find interfaces that provide object saving and retrieving behavior, called repository interfaces. The object saving behavior is not in the application core, however, because it typically involves a database. Only the interface is in the application core.
Out on the edges we see UI, Infrastructure, and Tests. The outer rings are reserved for things that change often. This approach to application architecture ensures that the application core doesn’t have to change as: the UI changes, data access changes, web service and messaging infrastructure changes, I/O techniques change.

The Onion Architecture relies heavily on the Dependency Inversion principle. The application core needs implementation of core interfaces, and if those implementing classes reside at the edges of the application, we need some mechanism for injecting that code at runtime so the application can do something useful. So tools like Guice, Ninject etc. are very helpful for those kind of architectures.

The application is built around an independent object model. The whole application core is independent because it cannot reference any external libraries and therefore has no technology specific code.

The inner rings define interfaces. These interfaces should be focusing on the business meaning of that interface and not on the technical aspects. So the shape of the interface is directly related to the scenario it is used in the business logic. The core takes ownership of these interfaces.

Outer rings implement interfaces, meaning all technology related code remains in the outer rings. The outermost ring can reference external libraries to provide implementations because it contains only technology specific code. This allows pushing the complexity of the infrastructure (which has nothing to do with the business logic) as far outwards as possible and…

Therefore, the direction of coupling is toward the center

That approach makes us independent of several infrastructure and crosscutting concerns:
- Database: The business rules do not depend upon the database (so storage can be swapped out)
- UI: The UI can change without changing the rest of the system
- Frameworks: The architecture does not depend on the existence of some library. This allows you to use frameworks as tools rather than having to cram your system into their limited constraints
- External agency: Business rules do not known anything about the outside world.
Which leads us to the ultimate benefit of this architecture…

The application core is testable. 100%
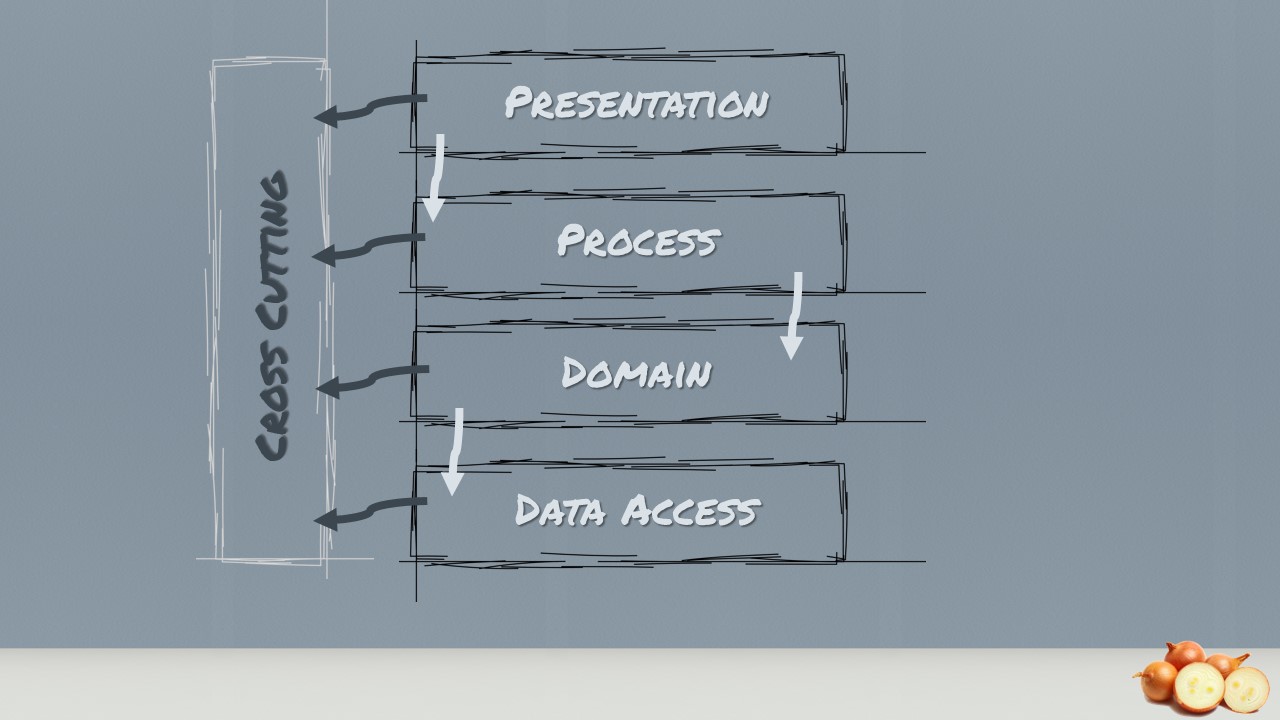
If we apply the principles of the Onion Architecture to the layered architecture we need to turn the layer diagram upside down.
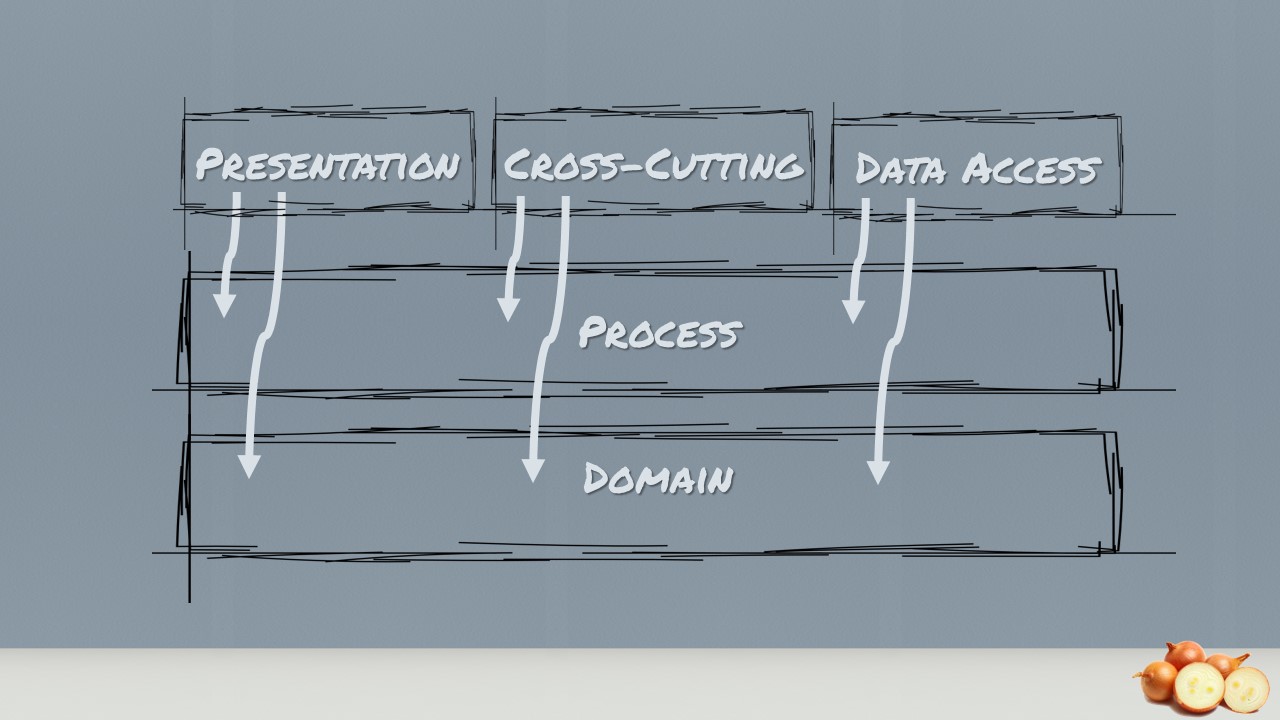
The key difference is that the Data Access, the presentation and the cross-cutting layer along with anything I/O related is at the top of the diagram and not at the bottom. Another key difference is that the layers above can use any layer beneath them, not just the layer immediately beneath. At least this approach could be achieved by using relaxed layering.
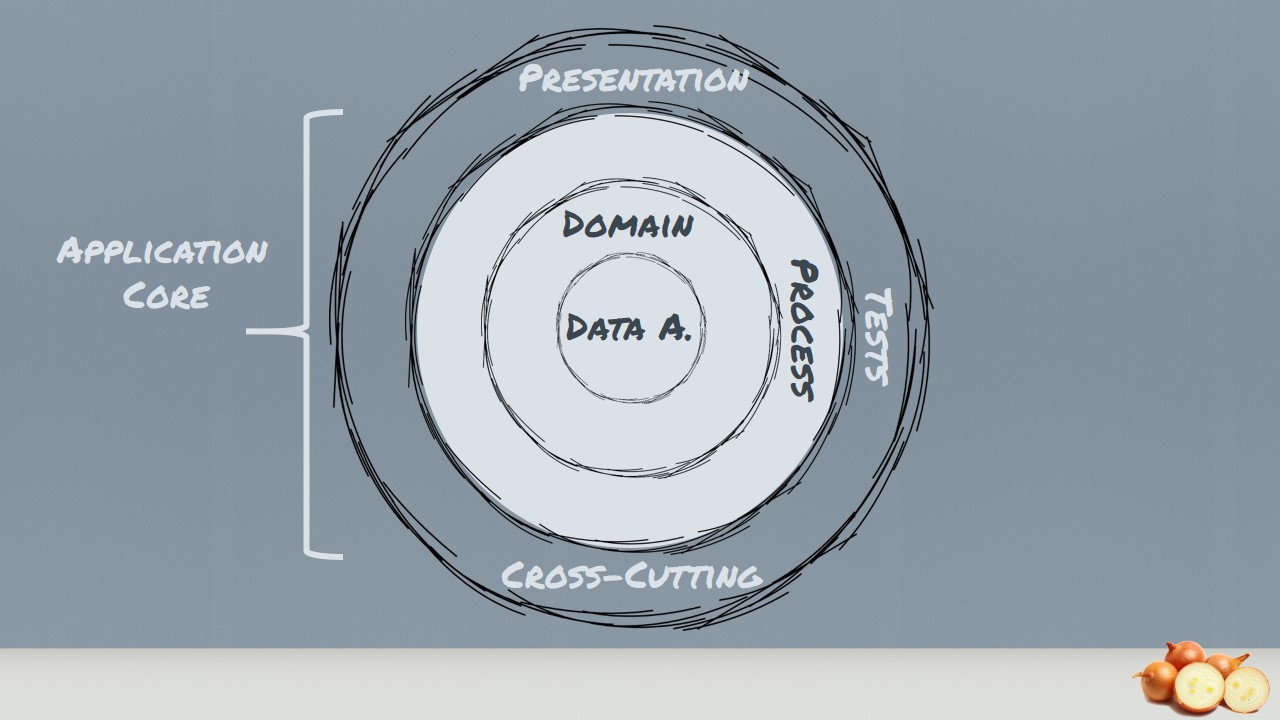
If we put the traditional layered architecture in concentric circles we clearly see the application is built around data access and other infrastructure. Because the application has this coupling, when data access, web services, etc. change, the business logic layer will have to change. The world view difference is how to handle infrastructure. Traditional layered architecture couples directly to it. Onion Architecture pushes it off to the side and defines abstractions (interfaces) to depend on. Then the infrastructure code also depends on these abstractions (interfaces). Depending on abstractions is an old principle, but the Onion Architecture puts that concepts right up front. But what about features or feature orientation?

We will not discuss how to introduce feature orientation because this has been covered by Urs Enzler’s presentation. The organization of the source code is independent of the architecture pattern you have chosen. Let us summarize what we learned.
https://github.com/danielmarbach/Onion.Factory

Don’t get hung on layers.

Ship onions instead. Kidding aside

We need to get the dependencies right and introduce just the necessary abstractions to have an independent application core.

References
- Alistair Cockburn Hexagonal Architecture http://alistair.cockburn.us/Hexagonal+architecture
- The Clean Architecture Uncle Bob http://blog.8thlight.com/uncle-bob/2012/08/13/the-clean-architecture.html
- Screaming architecture Uncle Bob http://blog.8thlight.com/uncle-bob/2011/09/30/Screaming-Architecture.html
- Growing Object Oriented Software Guided by Tests Designing for Maintainability Page 47-49
- Ports and Adapters With No Domain Model http://www.natpryce.com/articles/000786.html
- Improve Your Software Architecture with Ports and Adapters http://spin.atomicobject.com/2013/02/23/ports-adapters-software-architecture/
- Implementing Domain Driven Design Chapter 4 Hexagonal or Ports and Adapters
- The Onion Architecture : part 1 to part 4 http://jeffreypalermo.com/blog/the-onion-architecture-part-1/
- Creating N-Tier Applications in C# by Pluralsight http://pluralsight.com/training/courses/TableOfContents?courseName=n-tier-apps-part1 http://pluralsight.com/training/courses/TableOfContents?courseName=n-tier-apps-part2
- The Onion Architecture by Matt Hidinger http://matthidinger.com
- Software development fundamentals part 2 Layered architecture by Hendry Luk http://hendryluk.wordpress.com/2009/08/17/software-development-fundamentals-part-2-layered-architecture/
- Pattern-oriented Software Architecture – A System of Patterns Volume 1 Wiley Series
- Images from depositphotos and iconarchive
RT @planetgeekch: Chop onions instead of layers
http://t.co/NIye9MC5TA #architecture #onion #layer
RT @danielmarbach: RT @planetgeekch: Chop onions instead of layers
http://t.co/NIye9MC5TA #architecture #onion #layer
RT @danielmarbach: RT @planetgeekch: Chop onions instead of layers
http://t.co/NIye9MC5TA #architecture #onion #layer
RT @danielmarbach: RT @planetgeekch: Chop onions instead of layers
http://t.co/NIye9MC5TA #architecture #onion #layer
Some good thoughts here -> @danielmarbach @planetgeekch: Chop onions instead of layers
http://t.co/gl6Jpob4sn #architecture #onion #layer
@jjrdk @planetgeekch thanks!
RT @planetgeekch: Chop onions instead of layers
http://t.co/8SSeRtwQEk #architecture #onion #layer
RT @danielmarbach: RT @planetgeekch: Chop onions instead of layers
http://t.co/NIye9MC5TA #architecture #onion #layer
RT @danielmarbach: RT @planetgeekch: Chop onions instead of layers
http://t.co/NIye9MC5TA #architecture #onion #layer
RT @planetgeekch: Chop onions instead of layers
http://t.co/8SSeRtwQEk #architecture #onion #layer
@alek_sys good for us, like this concept! RT @planetgeekch: Chop onions instead of layers
http://t.co/xgmUflC5fY #onion #layer
Hi Daniel
Interesting onions, thanks for the presentation handout, pity I missed the presentation. greetings Damien
RT @danielmarbach: RT @planetgeekch: Chop onions instead of layers
http://t.co/NIye9MC5TA #architecture #onion #layer
RT @danielmarbach: RT @planetgeekch: Chop onions instead of layers
http://t.co/NIye9MC5TA #architecture #onion #layer
RT @danielmarbach: RT @planetgeekch: Chop onions instead of layers
http://t.co/NIye9MC5TA #architecture #onion #layer
RT @planetgeekch: Chop onions instead of layers
http://t.co/8SSeRtwQEk #architecture #onion #layer
>That approach makes us independent of several infrastructure and crosscutting concerns:
> UI: The UI can change without changing the rest of the system
That is indeed true : the ui CAN change.
But most of the time, if the application is big enough to have DDD, then the UI is really big and changing it is hardly possible.
You can REWRITE the UI in another language with another framework but this is so unpractical that it is rarely done.
IMHO, the better architecture is to have SMALL and INDEPENDENT applications : then you can really enjoy benefits like
* rewriting the UI (which is in my experience what is really hard otherwse BUT what the business wants most of the time, i.e if we could add a mobile application, if we could rewrite our flash based UI in HTML5, if …)
* change technology for one aplication (ex : user registration via database in java but messaging between users via scala actors and text processing for trend extraction in python )
That is not to say that DDD or onions are not good : indeed they allow to have coherency between the applications and eventually to reuse components between apps (for ex, reuse the persistence technology) but they are less important IMHO than decoupled applications.
@YellowBrickC http://t.co/FDPm55pS5j
レイヤーアーキテクチャには問題があるので、代わりにオニオンアーキテクチャを使うべき http://t.co/0CHLnin9FD
Very nice (and of course interesting) presentation!
How did you create the slides? Which tool(s) are you using for this “handwriting”-style?
Twenty years and more of architecture and we still promote layers???? WTF? #quote @danielmarbach http://t.co/atOpNcvogX
RT @jbandi @danielmarbach Twenty years and more of architecture and we still promote layers? http://t.co/MyYrWwBa2y #dddesign
RT @jbandi: Twenty years and more of architecture and we still promote layers???? WTF? #quote @danielmarbach http://t.co/atOpNcvogX
RT @jbandi: Twenty years and more of architecture and we still promote layers???? WTF? #quote @danielmarbach http://t.co/atOpNcvogX
Thanks Chris for your response. I like your thoughts on this topic. Let me give my own thoughts. I think following DDD principles doesn’t mean automatically a complex UI. I definitely agree that applying DDD principles makes only sense if the application domain has a certain complexity where you could benefit from the strategic and tactical patterns of DDD. But don’t forget: Behind DDD lays the principle of making complex domains simple, understandable and maintainable. This also applies to the User Interface. If you have a clear Bounded Context with a proper domain model underneath you have to talk to the business to get the tasks. This then ultimately leads to a more task based UI which is easier to maintain and also to switch out. Bluntly said you could argue that DDD leads to a simpler UI (because it’s task based) 😉
Regarding decoupling applications. I agree and I’m also a huge fan of proper service oriented architecture. BUT decoupling applications comes with a price and should not be taken lightly. I’m a bit tired and hopefully I can follow with some more insights into that topic some days later.
Daniel
A very nice wrap-up about onion architecture, thank you for sharing the presentation!
However, there’s a something that’s bothering me. Sometimes, you may have need to interact with some infrastructure parts from the inner layers. A good example will be logging – domain service may need to log some details or exceptions. How you would approach that?
To keep the right direction for dependencies (if you’re really committed to it) I see two possible options:
– Incorporating abstractions for required infrastructure parts into your domain. For example a generic ILog definition that will be implemented in outer layers.
– The outer layers will be “watching” the inner layers through domain specific messages/callbacks/errors/events and reacting to it accordingly.
In your experience is this a problem? How you will solve it?
[…] article about Onion Architecture has just been released in the Method and Tools Magazine. The article contains even more insights […]