This blog post is the written form of my presentation about how simplicity enables an evolutionary software architecture.

The main problem of modern software architecture
When we design a software system’s architecture, our main problem is that most modern software systems are complex systems.

Let me explain why:
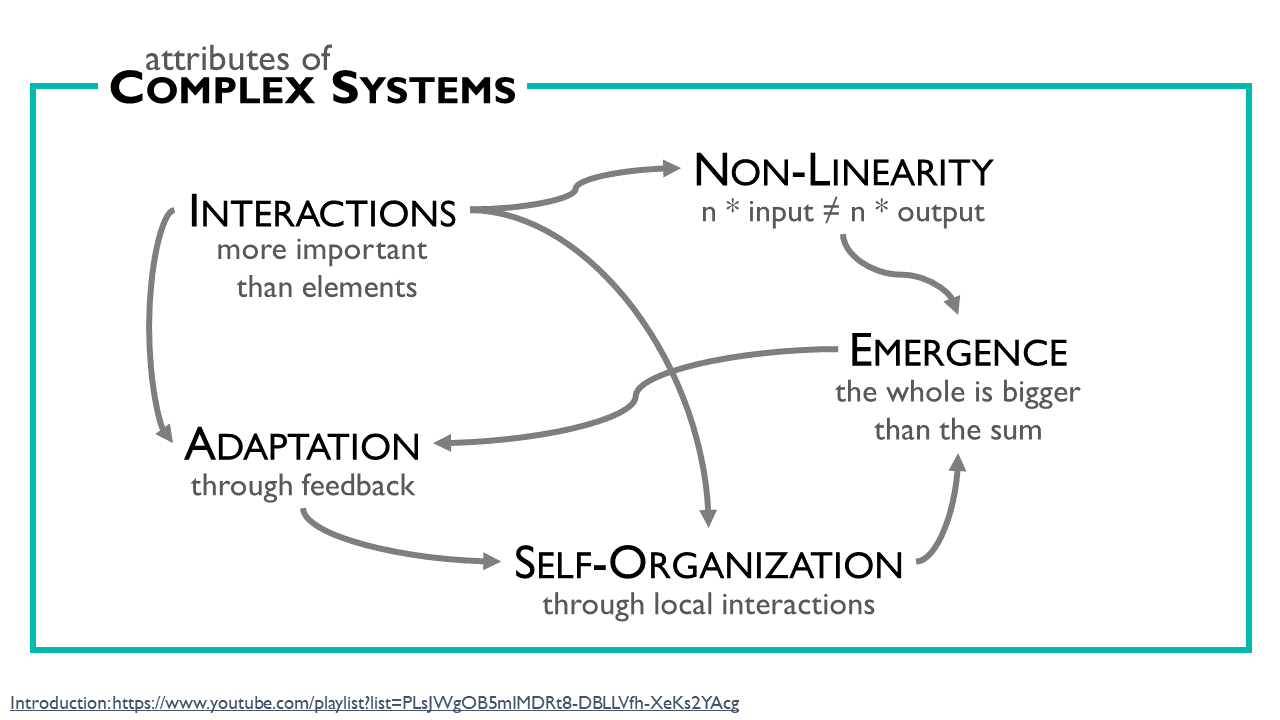
A complex system has typically the following 5 attributes:
Interactions are more important than the attributes of the elements
A complex system’s behaviour is mainly defined by the interactions of its elements and not by the attributes of the elements themselves.
If you have a distributed system, the interactions and communication, between the distributed parts are more relevant than the technology the part is written in.
Non-Linearity
In a non-linear system, when you, for example, double the input, the output may be the same, more, or even less. There is no linear correlation between input and output.
Introducing parallelism in computing does not necessarily make the computation faster because of the involved communication and state handling.
Emergence
The whole is bigger than the sum of the parts. The behaviours of its elements cannot explain the behaviour of the system.
We use week emergence every day to build our systems: Only the combination of e.g. a client providing the UI and a backend providing data and computation has the wished-for emergent behaviour we look for.
Strong emergence, on the other side, results in behaviours that weren’t predictable. Strong emergence is sometimes the reason for catastrophic system failures.
Adaptation through feedback
The elements change their behaviours as a result of the feedback they get from the system.
Our users tend to press F5 when they feel that the application is responding slower than usual. Of course, this is not helping at a moment when the system is already under load 🙂
Self-Organization through local interactions
Self-organization is a process in which a pattern at the global level
of a system emerges solely from numerous interactions among the system’s lower-level components. Moreover, the rules specifying interactions among the system’s components are executed using only local information, without reference to the global pattern.
Two problems with complex systems in daily live
In our daily work, we are confronted with complex systems, but we struggle to act well because of two reasons:

Counter-Intuitive
The behaviour of complex systems is counter-intuitive to us. It is hard for us to understand why adding more team members does not result in more outcome, but often less. Or why pair programming results in faster development although two people instead of one work on the same task.

No Repeatability
A property of complex systems that we forget regularly is that there is no repeatability in complex systems. If something worked once, there is no guarantee that it will work again. In a complex system, estimates cannot be based on experience; they are just hypothesis. Or copying an architectural style from a different context will probably end in different results.
Problem-solving approaches
We have to choose our problem-solving approach based on the kind of problem.
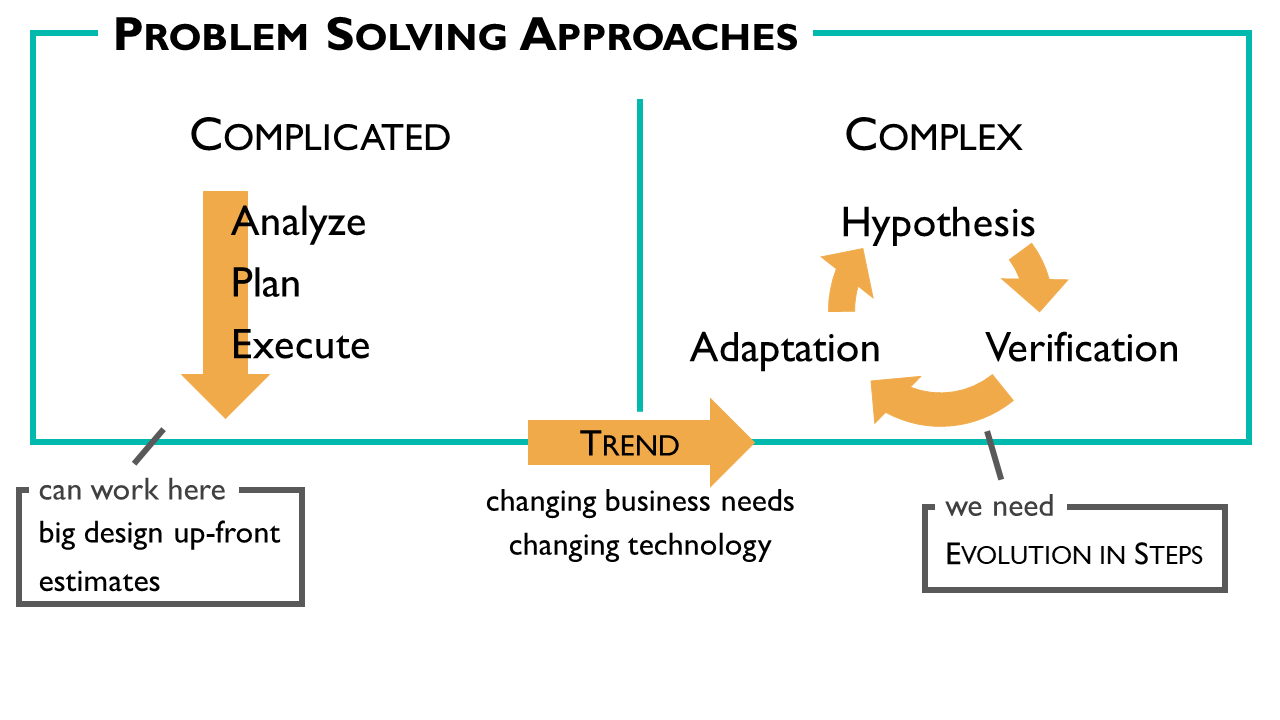
For complicated problems, we can have a straight forward approach with analyzing, planning and executing. This works because there will – if we work well – only small adjustments be necessary. For complicated problems, big design up-front and estimates can work.
For complex problems – or problems in a complex system – a different approach is compulsory because they cannot be analysed ahead. We cannot predict precisely what the outcome will be for a given action.
To tackle complex problems we use the approach of:
Hypothesis: Based on our current understanding, we formulate a hypothesis on what we can do to get closer to our goal.
Verification: We do as little as possible to verify or falsify the hypothesis.
Adaptation: Based on the new learnings, we strengthen what is right and weaken what doesn’t work.
Then we repeat until we are happy.
You may say: “but Waterfall – analyzing, planning, executing – worked in the past!”. I agree mostly. The reason is that 15 years ago, the software ecosystem was completely different. Single user rich clients running on a single platform were the norm. Nowadays, most systems are distributed, running in the cloud, running on multiple platforms (web, mobile, desktop, screen-less), and the trend goes clearly towards more and more complex solutions. There are two reasons for that: First, the business gets more complex by itself, and the technology allows us to solve problems that weren’t possible a couple of years ago. But many of these new technologies increase complexity, like the cloud – making every (cloud) system a distributed system.
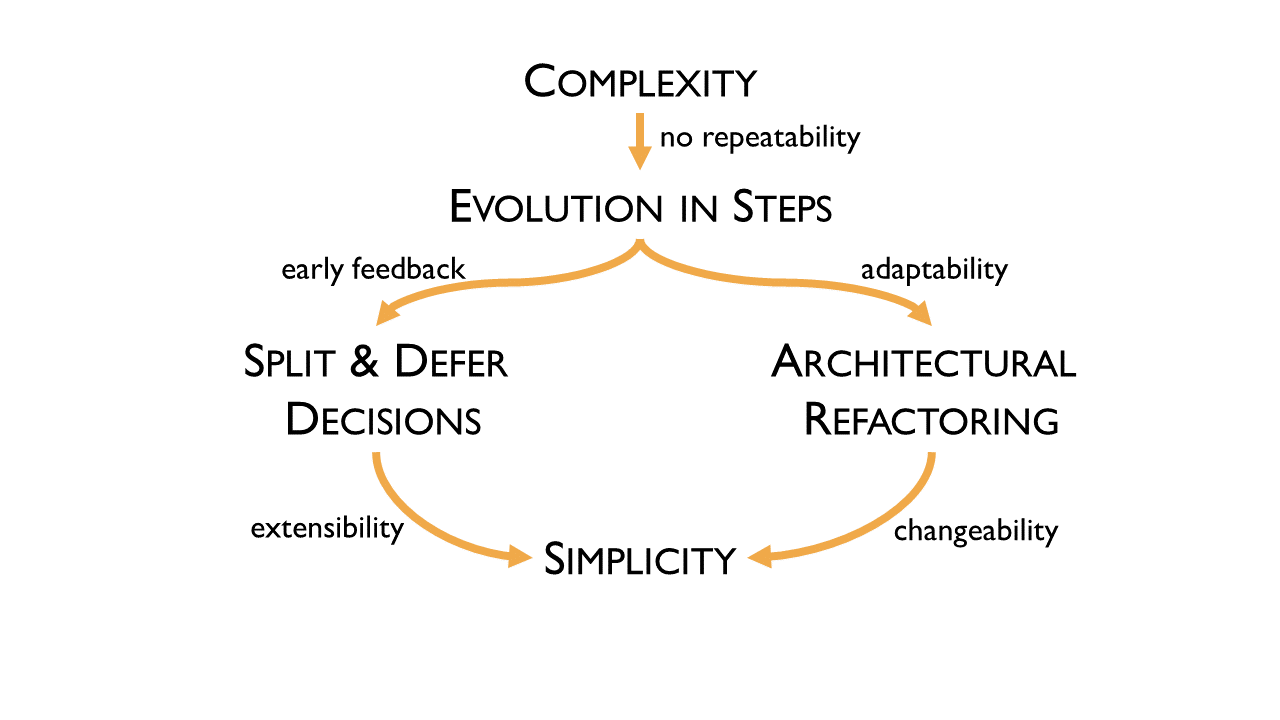
Evolution in steps
If we apply the Hypothesis – Verification – Adaptation cycle, we get a solution step by step. As a consequence, the architecture of a software system has to grow step by step, too.
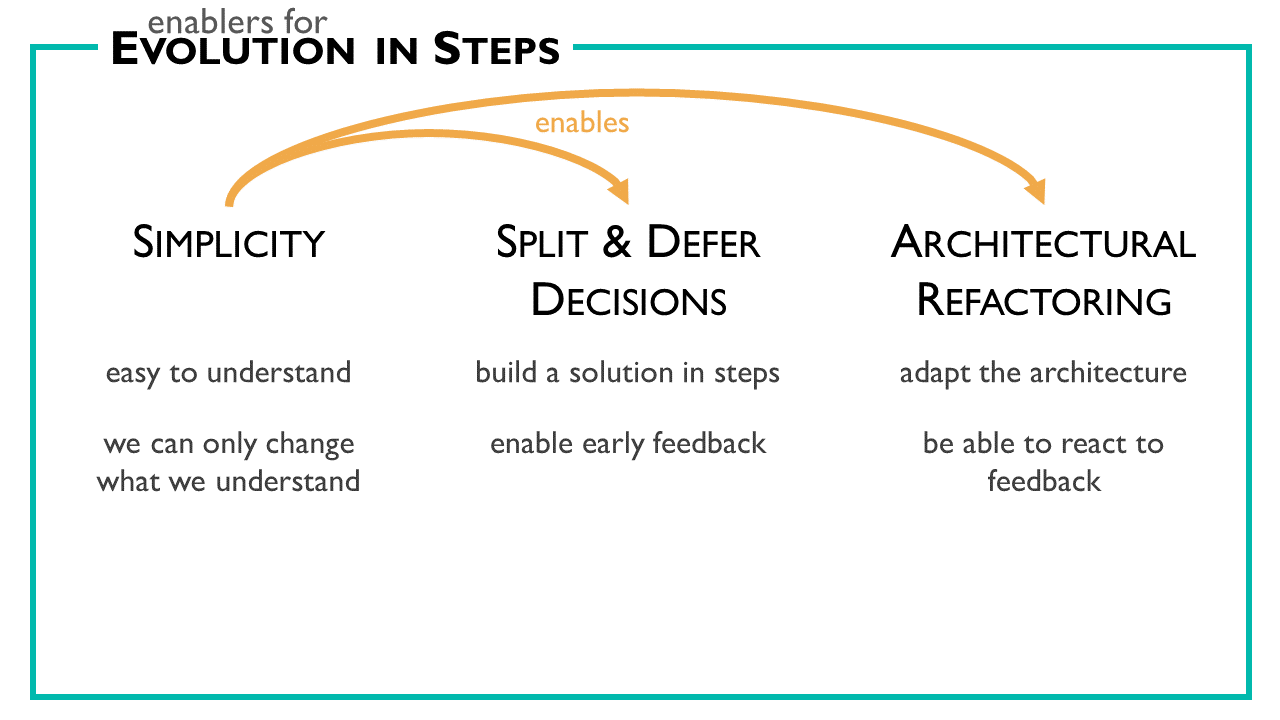
I recognised three enablers to for an evolutionary architecture:
Simplicity
Something is simple if it is easy to understand. We need this simplicity because, in a step-wise approach, we will change and extend most of the stuff we have already built, over and over again. And we can only change what we understand.
Split & defer decisions
So we can build an architecture in steps, we need to learn to split decisions and defer the sub-decisions to different steps on the way. This allows us to get feedback and verify our hypothesis early and often.
Architectural refactoring
If we work in steps and adapt to our learnings, we won’t build the correct architecture on the first attempt. We’ll need to adapt the architecture based on the feedback we get.
Simplicity additionally helps to enable split & defer decisions and architectural refactoring.
Simplicity
This is a model to discuss simplicity in software architecture and design:

A solution to a problem can be either specific or generic.
Specific = a solution to a single problem
Generic = a solution for several problems
A solution is also somewhere on the continuum from concrete to abstract. For example, a chair is a bit abstract but still quite concrete – Furniture would be more abstract, “the red chair with a dragon sticker belonging to my daughter Nora” would be very concrete.
We humans can understand concepts and solutions on the lower right – towards specific and concrete – much easier than generic and abstract solutions. There is no hard boundary but a tendency. While we can cope with a little abstraction quite well, generic solutions quickly become hard to comprehend.
Therefore it is a really bad idea to start a new software product by developing a framework first because a framework is a rather generic and abstract solution – if it ever really solves the concrete and specific needs later anyway.
We should start with concrete, specific solutions. We should only take a step towards abstraction or genericity when it helps overall simplicity because of much less code in return. Smaller things are generally simpler than big things.
Our solutions, therefore, tend to walk slowly from the concrete-specific corner towards the generic-abstract corner. Luckily, if we invest time into refactoring and reflecting our understanding of the problem and its solution, we will have so-called simplicity insights – Aha! moments. An insight that we can achieve the same thing with a simpler solution. Then we can push our solutions a bit back to the simpler concrete-specific corner.
Tips for simple software design

To keep our software design simple and changeable, it should reflect the user’s mental model.
When our users talk about emails, letters and documents, we should not map that to a more abstract design like text-content-holders. Once you realize that your users understand documents to consist of pages, you get into trouble to adapt your abstract design. If you’d used exactly the model as understood by your users, you could easily follow their change wishes. While abstractions can be helpful, it is tough to get abstractions that hold when users’ needs change and are not leaky. Therefore abstractions should only be added in hindsight.

When we need to model a book in the software we have two options.
Option 1: We can base our model on entities. We look at the book and enumerate its properties. The book has a title, author, ISBN, ratings and a price.
Option 2: we look at the behaviours that we can apply to a book. We can create a book in our catalogue, correct a typo in the title, add a rating, set a price and so on.
Modelling entities leads most of the times too heavily tightly coupled models because everything goes into the book’s one container – or a book aggregate or service in DDD-speak.
Modelling based on behaviours naturally leads to loosely coupled models. There will probably be a model for the book’s physical properties (title, author, ISBN), another model for ratings, and a third pricing model. Every model is specific for enabling its according behaviour.
In reality, there are not only these two extreme options but a continuum. However, in my experience, thinking in behaviours results in more straightforward designs and code.
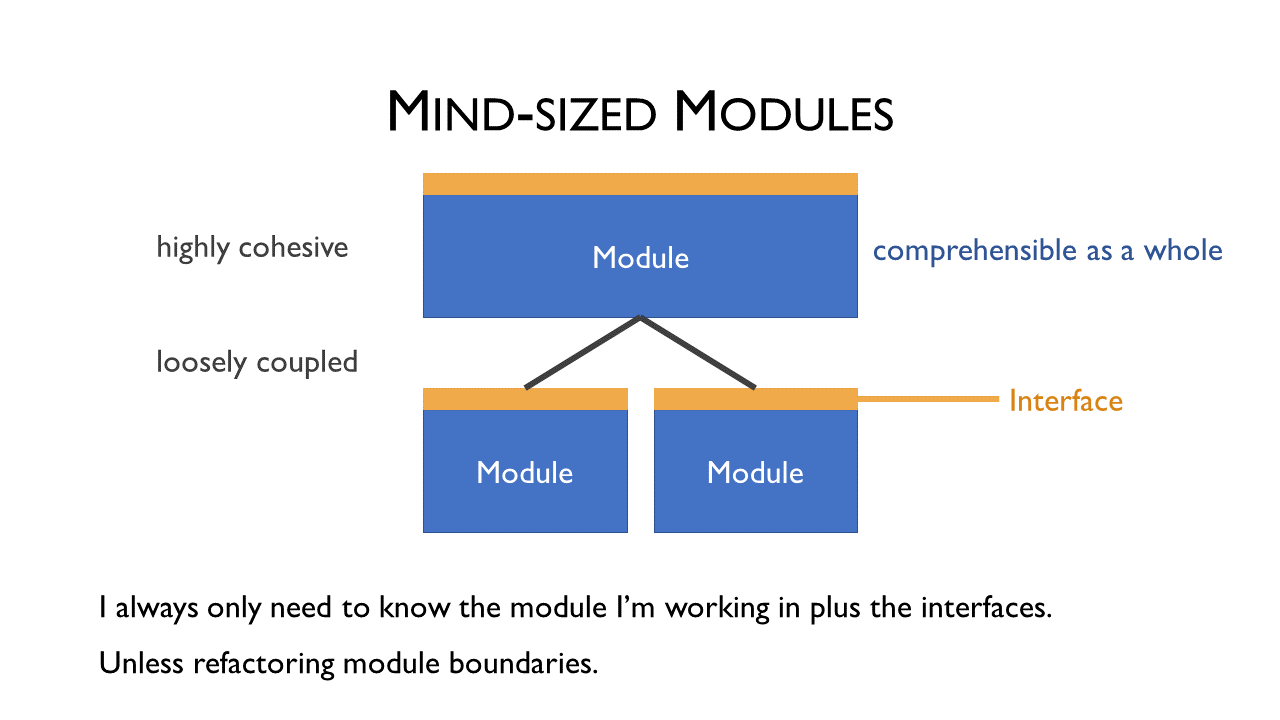
Our brain is limited to how many things we can have in mind at once. Changing software is hard because we need to understand the consequences so that we don’t introduce defects. Therefore, we modularise our software. When working inside a module the only things we need to know are how the module works on the inside, all the interfaces of other modules we interact with, and what contract we have to fulfil for the module’s interface.
A module should not get bigger than what we can oversee as a whole. Therefore, I call them mind-sized modules.
High cohesion inside a module helps to keep the code free of unnecessary abstractions. As we have seen before, less abstract is most of the times simpler.
However, modules should be loosely-coupled to each other by limiting the number of dependencies and data that is exchanged. This makes the understanding of interactions between modules simpler.

To make our software easy to change and adapt, it should be flexible and configurable. NO! Absolutely not. Flexibility and configurability add a lot of complexity because the software has to run with all possible configurable values and all variations of the flexible part. Instead, we should hard-code as much as possible, and if it needs to change, we should change the code and quickly deploy it to the live system. We continuously deliver exactly the version of the software that is currently needed.
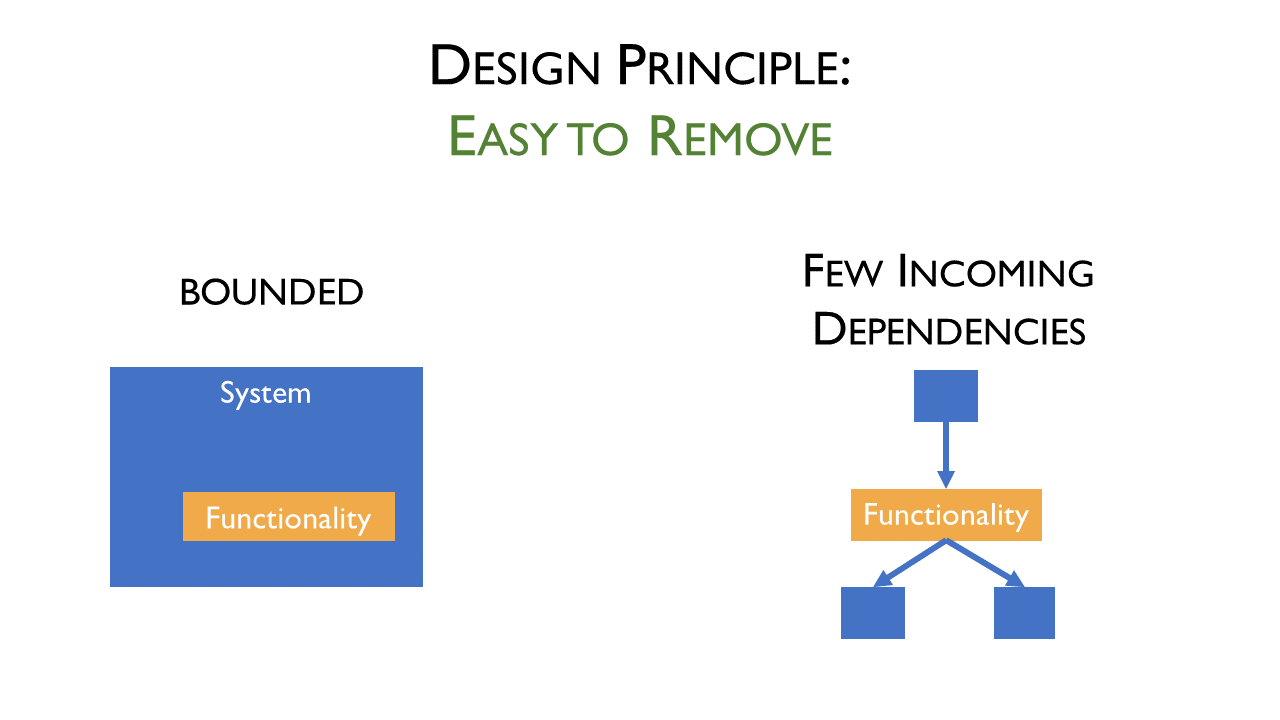
When I add new functionality to our software, I ask myself: “how can we get rid of this easily, when we don’t need it anymore?” This is essential because most functionalities are replaced at least once. There are many reasons: we built the wrong thing, we have now a better way to solve the same thing, technology changed, the architecture needs to change and so on.
Two tips to add code in a way that it remains easy to remove:
Tip 1: add the new functionality in a bounded way. No other code knows the new functionality. Only the new functionality knows some existing code to interact with it.
Tip2: if you can’t add the new functionality in a bounded way, make sure that there are only a few incoming dependencies. Only little existing code knows about the new functionality.
The result is a design with a (hopefully) stable core surrounded by lots of mostly independent features.
It is okay when individual functionalities share, for example, identifiers to identify a piece of data like a customer. But there should be as little code dependencies as possible between different functionalities.
Split & Defer Decisions
The second enabler for an evolutionary architecture is splitting and deferring decisions.

We split every architectural problem, like persistency, into sub-problems that can be solved one after the other.
Then we find an overall concept. We define a coarse plan for how we get to the desired end state. This helps prevent dead-ends when we go step by step and not lose sight of the big picture.
Solving sub-problem per sub-problem allows us to get feedback early and adapt our overall concept if necessary. We continue until all sub-problems are solved – including the sub-problems that we newly discover on the way.
Let’s look at an example, persistency:

If we think about a typical application, then it is clear that we need to persist some data. However, for the first couple of days or weeks, we actually don’t need it. We can build an application holding all data in-memory and already get feedback from our stakeholders to make sure that we can solve the core business problem. Ignoring persistence at the beginning helps us to focus on the core business problems, and not to get distracted by infrastructure problems.
Once we are ready for the next step, we separate the business logic from the persistency code so that changes to the persistency code does not impact the business logic.
When we have implemented a good part of the business logic, we should know what kind of data – its form a amount – we probably will have persist when the system will be live. With this knowledge, we are capable to decide how we want to store data: relation, document-based, key-value store, graph-based, or something else.
Now we have a system that can go live.
When the amount of data rises, we will probably be confronted with how to scale the database. Then we decide whether we scale horizontally, vertically, with a mix of both, or whether we don’t even need any scaling.
While we advance in steps, it is crucial to always have an overall plan of possible options to don’t run into a dead-end and still keep progressing.

At the start of building a new software system, you should plan your steps not only for persistency but for all of the above 23 aspects of software architecture. Not all may apply in your situation, but you should think about all of them and decide which apply and build an initial coarse plan on how to progress step-wise.
Architectural Refactoring
The third enable for an evolvable architecture is continuous architectural refactoring.
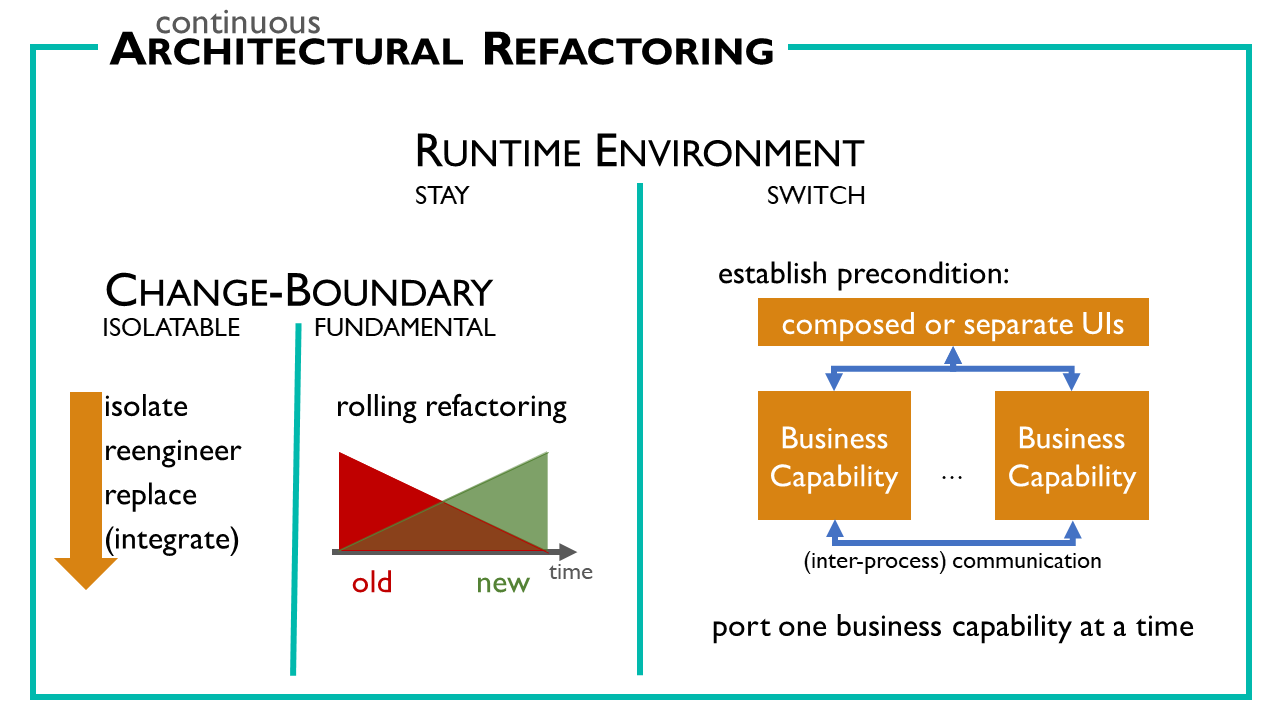
When refactoring an architecture, we have to distinguish between different scopes. First: do we stay on the same runtime, or do we switch runtimes, like switching from FoxPro to .Net. If we stay, we can look at the boundary of the change that we want to make: is the change isolatable, or is it a fundamental change that affects a big part of the system.
In the case of an isolatable change, we first isolate the change by pushing all the code that needs changes behind an abstraction. This abstraction allows us to replace the code inside by reengineering it. Finally, we may integrate the changed code back into the rest of the code if this helps simplicity.
In the case of a fundamental change that cannot be isolated, we apply a rolling refactoring. For a while, there co-exist both the old and the new architectures. Then we port piece by piece from the old into the new architecture. This is most of the times only possible by adding additional code that supports having two worlds in the same code, like scaffolding or detours. The extra effort is paid back because even during the refactoring, we always have a running system. Maybe the system runs a bit slower because of the additional helper code, but it runs, and we can continue adding, changing and getting feedback.
In the case of a runtime environment switch, we should first refactor the old system to meet the precondition as shown on the slide. We have to get the old system into a form that allows us to port slice by slice – just as in the rolling refactoring case. However, since we switch the runtime environment, communication between the slices will become inter-process communication. If possible, we should strive to have a slice per business capability because that minimizes communication between the slices.
However, many teams I met have the problem that they don’t have the time to refactor the architecture. Their capacity is consumed mainly by having to deliver features, fixing defects, and providing support. Here is a tool that might help you if you are in the same challenging situation.
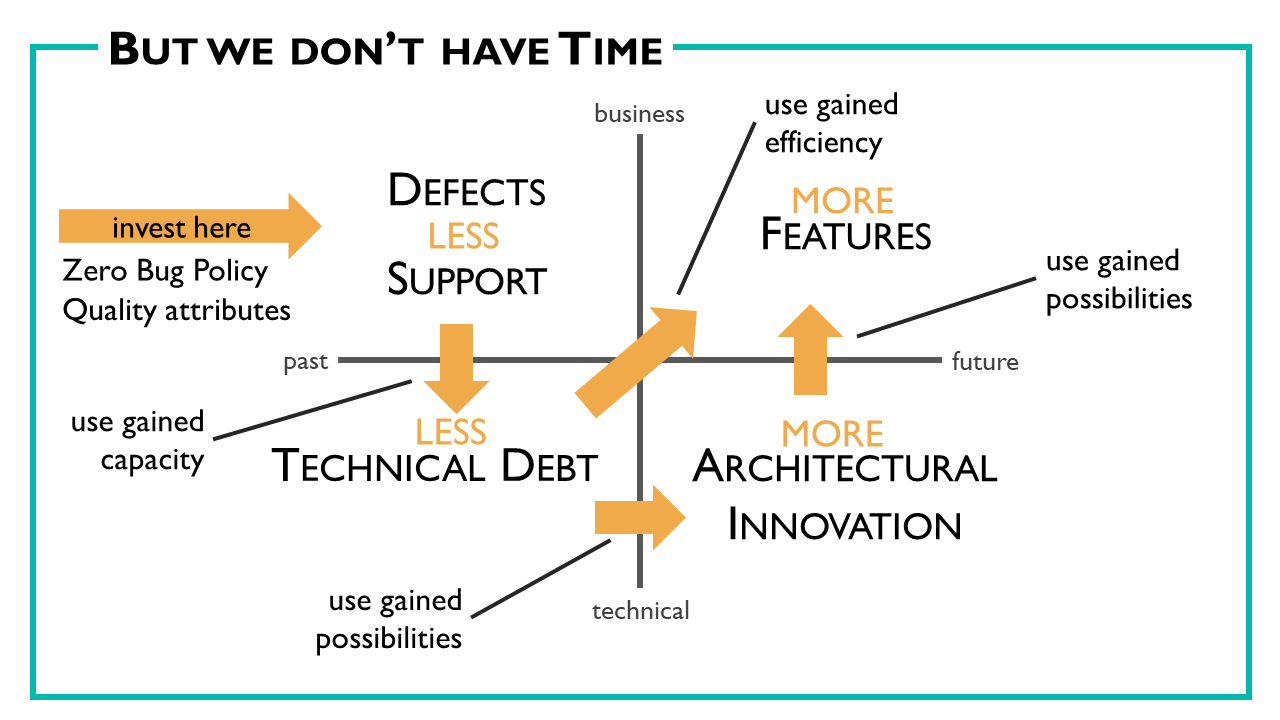
Consider the above slide with its four quadrants. On the vertical axis, we have at the top things that are related to the business. Items that are interesting for the stakeholders. At the bottom, we have technical issues. On the left, we have things that come to us back from the past. On the right, we have items for the future.
On the top right – for the business and the future – are new features. Features will improve our product for our users in the future. On the top left – for the business coming back to us from the past – we have defects and support. On the bottom left – technical and coming from the past – we have technical debt: stuff we would do differently today. And on the bottom right – technical and for the future – we have architectural innovation that allows us to deliver new features not possible in the current architecture.
It is a good exercise to look back at the last 12 month and write down the percentage of your teams capacity that went into which quadrant. Then write down what you think would be a good distribution. Also, ask your managers, you might get surprised.
But how to change the percentages? I suggest to first invest in the top left. Let us bring down the number of defects and the need for support by introducing a Zero Bug Policy: if a bug is found it is either fixed quickly or never. This frees you from managing a whole backlog of known bugs and typically improves quality already a lot. Furthermore, we should invest in improving the quality attributes that are most relevant to get support down. When we did this, we should get some free capacity to invest in the bottom right to lower the technical debt. Once the pressure from technical debt goes down, we get two effects: The first effect is that we can deliver more features with the same capacity. This is so because less technical debt means, we need less effort to build a new feature. The second effect is that we can use to improved efficiency to find time for architectural innovation. And architectural innovation gives us the possibility to deliver new features that were not yet possible.
Summary
A complex software development effort needs to advance in steps because, in complex systems, there is no repeatability and predictability. A software architecture that enables working in steps can only be built when we split the architectural decisions and defer the sub-decisions, and when we are capable of refactoring the existing architecture to adapt to new learnings. Both are only possible when we value simplicity because simplicity enables all of the above. Simplicity enables extensibility, to be able to add new stuff, and enables refactoring because it keeps the system changeable.
Thanks for reading this long blog post. If you think that I might help you regarding designing your software architecture, contact me – you find my coordinates on the next slide: